SQLで羃等にDBスキーマ管理ができるツール「sqldef」を作った
sqldefのリポジトリ
これは何か
Ridgepoleというツールをご存じでしょうか。
これはRubyのDSLでcreate_tableやadd_index等を書いてスキーマ定義をしておくとそれと実際のスキーマの差異を埋めるために必要なDDLを自動で生成・適用できる便利なツールです。一方、

で言われているように、Ridgepoleを動作させるためにはRubyやActiveRecordといった依存をインストールする必要があり、Railsアプリケーション以外で使う場合には少々面倒なことになります。*1 *2
そこで、Pure Goで書くことでワンバイナリにし、また別言語圏の人でも使いやすいよう、RubyのDSLのかわりに、誰でも知ってるSQLでCREATE TABLEやALTER TABLEを書いて同じことができるようにしたのがsqldefです。
使用例
現時点ではMySQLとPostgreSQLに対応しているのですが、このツールはmysqlコマンドやpsqlコマンドとインターフェースを揃えるため、 それぞれのDBに対しmysqldef、psqldefという別のコマンドを提供しています。
README用にgifアニメを用意しておいたので、こちらで雰囲気を感じてください。
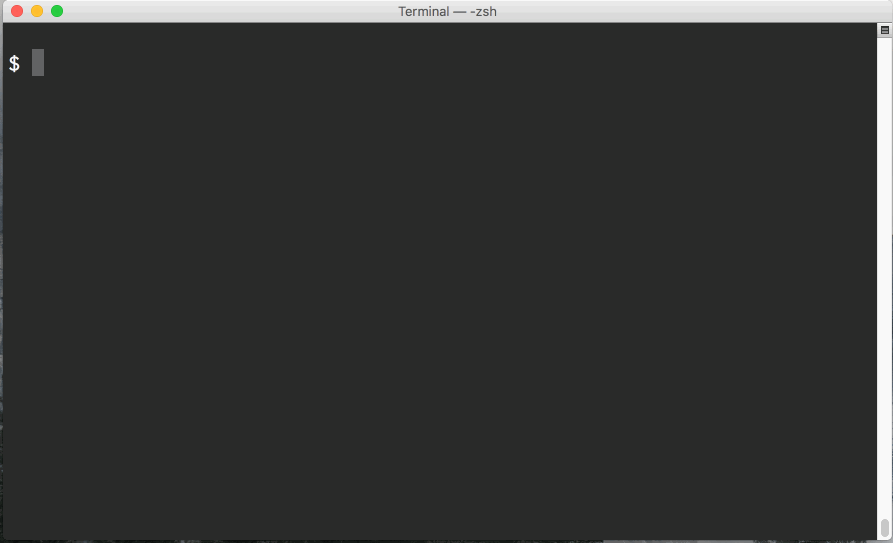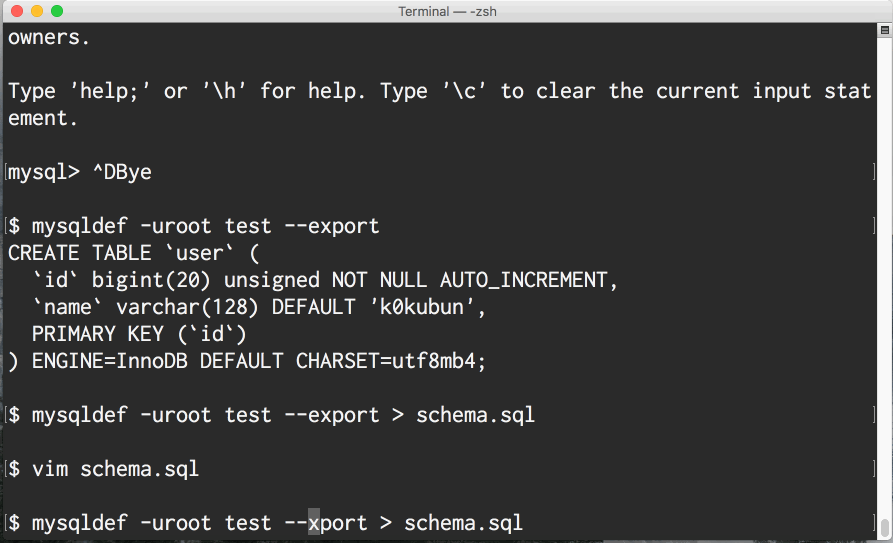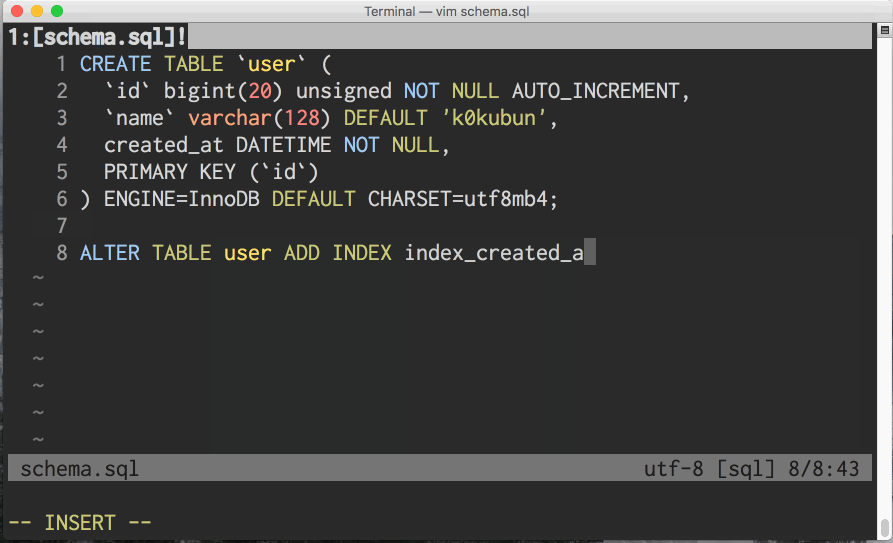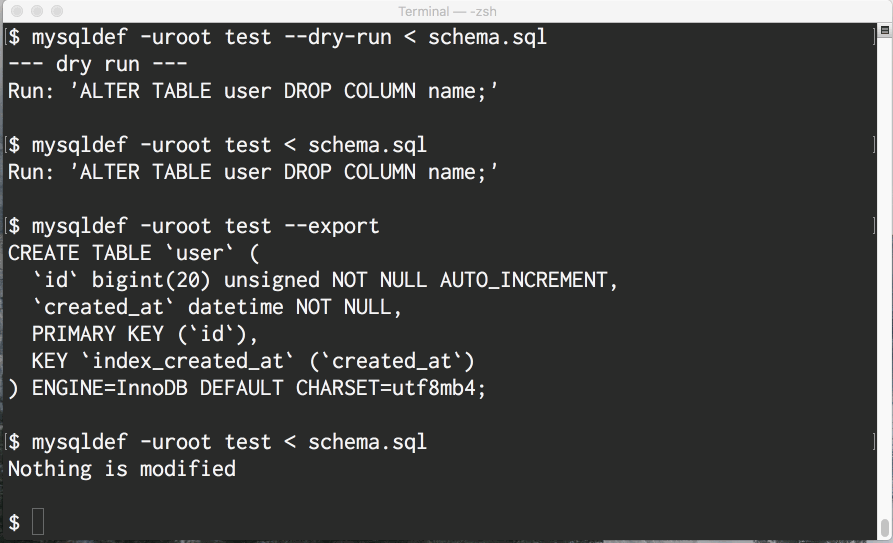
どうやって動いているのか
mysqldef
簡単ですね。go-sql-driver/mysqlというPure GoのMySQLのDBドライバを使っており、mysql(1)やlibmysqlclientに依存していません。
psqldef
これもlib/pqというPostgreSQLのDBドライバがPure Goのため、こちらもpsql(1)やlibpqに依存していません。
pg_dump への依存は、クエリだけでスキーマを取れるようにし、そのうちなくせたらいいなと思ってます。
実装済の機能
- MySQL
- カラムの追加、変更、削除
- テーブルの追加、削除
- インデックスの追加、削除
- 外部キーの追加、削除
- PostgreSQL
- カラムの追加、削除
- テーブルの追加、削除
- インデックスの追加、削除
- 外部キーの追加、削除
あまり無駄にシミュレートをがんばりたくないのと、どうせ対応しても僕は使わないので、CREATE TABLE, CREATE INDEX, ALTER TABLE ADD INDEX の羅列以外の入力に対応していません。DROPは常に書いてあるものを消すことで生成する想定です。テーブルやカラムにリネームが必要な場合は手動でリネームを発行して --export し直す想定です。
お試しください
まだ本番じゃ全然使えないクオリティなんですが、ISUCONとかでは割と便利に使えるかもしれません。 sqldefがそのまま使えるスキーマ定義が置いてあることが多いようですし。
そういうわけで、よろしくお願いします
追記: schemalexとの比較
schemalexの作者の方にschemalexと比較して欲しいというコメントをいただいているので軽く補足します。
SQL同士を比較してSQLを生成する既存のマイグレーションツールはいろいろあるんですが、その中でもGo製でMySQL向けにスキーマ生成ができるschemalexが既にある中で何故一から作ったかというと、正直なところ完全に調査不足で羃等にスキーマ管理するツールをRidgepole以外に知らなかったことによります。
その上で、2018年8月現時点でsqldefに実装されている機能とschemalexを比較すると、それぞれ主に以下の利点があると思います。
- schemalex
- sqldef
どれもお互い今後の開発次第で解決できる問題ですが、おそらく思想的に変わらなそうなのはそれぞれ最後のCLIに関する部分でしょう。なので、私が羃等なスキーマ管理ツールのユースケースとして想定している以下の状況における、それぞれの現時点での使い方を比較したいと思います。
DBサーバーのスキーマのexport
schemalex
$ echo "" | schemalex -o schema.sql - "mysql://root:@tcp(localhost:3306)/test"
BEGIN; や COMMIT; が含まれているのを消す必要があるため、私が把握していないだけでより正しい方法があるかもしれません。
sqldef
$ mysqldef -uroot test --export > schema.sql
Pull Requestマージ後に実行されるDDLの表示、適用
schemalex
もともとgit-schemalexとして開発されていた機能が活用できるため、こちらはschemalexが便利なユースケースだと思います。
# PRチェックアウト時、masterのスキーマ適用のためのDDL表示 $ schemalex "mysql://root:@tcp(localhost:3306)/test" "local-git://.?file=schema.sql&commitish=master" BEGIN; SET FOREIGN_KEY_CHECKS = 0; CREATE TABLE `users` ( `id` BIGINT (20) DEFAULT NULL, `name` VARCHAR (40) DEFAULT NULL ); SET FOREIGN_KEY_CHECKS = 1; COMMIT; # PRチェックアウト時、masterのスキーマの適用 $ schemalex "mysql://root:@tcp(localhost:3306)/test" "local-git://.?file=schema.sql&commitish=master" | mysql -uroot test # マージ後に実行されるDDLの表示 $ schemalex "mysql://root:@tcp(localhost:3306)/test" schema.sql BEGIN; SET FOREIGN_KEY_CHECKS = 0; ALTER TABLE `users` ADD COLUMN `created_at` DATETIME NOT NULL; SET FOREIGN_KEY_CHECKS = 1; COMMIT; # マージ後のスキーマの適用 $ schemalex "mysql://root:@tcp(localhost:3306)/test" schema.sql | mysql -uroot test
sqldef
sqldefは標準でgit連携を持っていないため、mysqlコマンドが不要なかわりにgitコマンドが必要になります。*4
# PRチェックアウト時、masterのスキーマ適用のためのDDL表示 $ git show master:schema.sql | mysqldef -uroot test --dry-run -- dry run -- CREATE TABLE users ( id bigint, name varchar(40) DEFAULT NULL); # PRチェックアウト時、masterのスキーマの適用 $ git show master:schema.sql | mysqldef -uroot test -- Apply -- CREATE TABLE users ( id bigint, name varchar(40) DEFAULT NULL); # マージ後に実行されるDDLの表示 $ mysqldef -uroot test --dry-run < schema.sql -- dry run -- ALTER TABLE users ADD COLUMN created_at datetime NOT NULL; # マージ後のスキーマの適用 $ mysqldef -uroot test < schema.sql -- Apply -- ALTER TABLE users ADD COLUMN created_at datetime NOT NULL;
なおBEGIN;やCOMMIT;は表示していませんが、applyはトランザクション下で行なわれます。
最新のスキーマファイルのDBサーバーへの適用
schemalex
# masterチェックアウト時、スキーマ適用のためのDDL表示 $ schemalex "mysql://root:@tcp(localhost:3306)/test" schema.sql BEGIN; SET FOREIGN_KEY_CHECKS = 0; ALTER TABLE `users` ADD COLUMN `created_at` DATETIME NOT NULL; SET FOREIGN_KEY_CHECKS = 1; COMMIT; # スキーマの適用 schemalex "mysql://root:@tcp(localhost:3306)/test" schema.sql | mysql -uroot test
sqldef
# masterチェックアウト時、スキーマ適用のためのDDL表示 $ mysqldef -uroot test --dry-run < schema.sql -- dry run -- ALTER TABLE users ADD COLUMN created_at datetime NOT NULL; $ mysqldef -uroot test < schema.sql -- Apply -- ALTER TABLE users ADD COLUMN created_at datetime NOT NULL;
まとめ
どちらのCLIがユースケースにマッチするかは要件によると思いますが、2018年8月現時点では、MySQLの用途においては実績のあるschemalexを採用するのが現実的だと思います。私自身は自分の自由が効くsqldefをMySQLでも使いメンテを続けるつもりのため、時間が経てばこの問題は解決するでしょう。
一方PostgreSQLでワンバイナリのスキーマ管理ツールが必要な場合は、PostgreSQL未対応のschemalexに対応を入れるよりはsqldefを使ってしまう方が楽かと思われます。
2021-10-30 edit: おかげ様で様々な会社様から本番利用事例をいただいております。まだまだ全てのケースに対応しているとは言えずissueベースでユースケースのカバーを続けている状態ですが、公開から3年以上経った今、schemalexやskeemaと比べても遜色ない利用実績があると言えるでしょう。
言及例:
- 2018-09-05: sqldef本番投入成功
- 2019-12-07: Web開発を支えるマイグレーションツールについて
- 2020-07-30: Nature Remoから学ぶシステムアーキテクチャと開発プロセス w/ songmu *5
- 2020-11-05: ZOZOTOWNリプレイスにおけるSREの取り組み
- 2021-09-27: sqldefへのSQL Server対応のコントリビュート 〜OSS活動を通して紐解くDBマイグレーションツールの実装〜 - ZOZO TECH BLOG
- その他: 利用者が多くを占める sqldef contributors
*1:例えばRuby以外の言語でアプリを書いてCircleCIでテストする場合、CirlceCI公式のDockerイメージは普通に一つの言語しか入ってないので、アプリ用の言語とRidgepole用のRubyが両方入ったDockerイメージを自分で用意しないといけないですよね
*2:Ridgepoleの作者のwinebarrelさんにコメントをいただいてますが、現在はomnibus-rubyによってRubyを同梱したrpmやdebのパッケージとしても配布されているため、バイナリをダウンロードするかわりにパッケージをダウンロードしてインストールする、ということもできそうです。一方手元でmacOSを使っていたりするとrpmやdebは使えないですし、これはItamaeとmitamaeに関しても言える話ですが、一切依存のないバイナリ一つで動作する方が何かと管理が楽であろうという考えのもとこれらのツールを作っています。
*3:schemalexでもこのPR https://github.com/schemalex/schemalex/pull/52 で同様の機能が実装されると理解していますが、未マージのようです
*4:GitHubにリポジトリを置いていたらCIからcloneしてくる際に必要になるので、普通は入ってるとは思います
*5:00:25:10~: "多分sqldefの方が使われていると思うんですけど" と言及いただきました
RubyのJITに生成コードのメモリ局所性対策を入れた話
JITすればするほどRailsが遅くなる問題
Rubyの次期バージョンである2.6には、バイトコードをCのコードに変換した後、gcc/clangでコンパイルして.soファイルにしdlopenすることで生成コードのロードを行なう、MJITと呼ばれるJITコンパイラが入っているのだが、マージしたころのツイートにも書いていた通り、Railsで使うとより多くのメソッドがJITされるほど遅くなってしまうという問題があった。
結果、"MJIT slows down Rails applications"というチケットが報告されることとなり、昨日までの5か月の間閉じることができなかった。
元の構成

対策を始める前のMJITは大雑把に言うとこういう感じだった。メソッド1つごとに1つの.soファイルが作られ、ロードされる。
無制限にロードしまくるわけではなく、--jit-max-cacheオプションで指定した数(デフォルトでは1000)までしか生成コードを維持しないようになっており、JITされた数が--jit-max-cacheに到達すると、「呼び出し回数が少なく、かつ現在呼び出し中でないメソッド」と「メソッドがGC済のメソッド」向けにdlcloseを行なってから、他の呼び出し回数の多いメソッドのJITを開始する。
遅くなる理由
JITのためにgccやclangが走っている最中は、そこにリソースが取られるからかある程度遅くなってしまうのだが、今回報告されたチケットの計測方法では計測中ほとんどコンパイルが走らない状態になっていた。
いくつかのマイクロベンチマークや、ピュアRubyのNESエミュレータでの性能を計測するOptcarrotというベンチマークではJITした方が明らかに速いのだが、先のチケットの計測方法だと遅くなってしまう。この理由は最初は不可解だったが、Optcarrotで普通にベンチを取ると20〜30メソッドくらいしかJITされないのに対し、このRailsでの計測は4000〜5000メソッドがJITされているという大きな違いがあった。
そもそも生成コードの最適化がRailsのコードに対して全然効いてなさそうなのも問題なのだが、最適化の余地が全くないようなただnil*1を返すだけのメソッドをたくさん定義して呼び出してみると、定義して呼び出すメソッドの数が多いほど遅くなることが発見された。
perfで計測してみると、遅くなっているのはicacheにヒットせずストールする時間が長くなっているのが原因のようで、それはメソッドごとに.soをdlopenしていることで生成コードが2MBおきに配置されてしまっておりメモリ局所性が悪いことが原因と結論づけた。*2
どうやって解決するか
解決策1: ELFオブジェクトを直接ロード
僕がこれに関する発表をRubyKaigiで行なってすぐ、shinhさんがELFオブジェクトを自力でロードしてくるパッチを作ってくださっていた。試してみると、ロードにかかる時間を遅くすることなく、40個くらいのメソッドを呼び出してもJIT無効相当の速度が出ていた。
一方で、shinhさん自身がブログで解説しているが、これを採用するとなると以下のような懸念点があった。
- ELFを使うOSでしか動かない
- (現状のパッチだと)ロードしたコードのデバッグ情報がgdbで出ない
- ローダ自体の保守やデバッグが大変そう
- 生成コードのメモリ管理が大変 (1GB固定アロケートか、遅くなるモードのみ実装されている)
そのためこれは直接採用はせず、以下の手法の評価にのみ利用した。
解決策2: 全てのメソッドを持つsoファイルを作ってdlopen
別々の.soになっているから問題が起きるわけなので、何らかの方法でコンパイル対象のメソッドが全て入ったsoを生成し、全てのコードをそこからロードしてくれば良いという話になる。コンパイル対象のメソッドの数が適当にハードコードした数に達したらまとめてコンパイルしてロードするようにしてみたら、実際速かった。
考慮したポイント
しかし、4000メソッド(計測に使われているRailsアプリのエンドポイントを叩いて放置するとコンパイルされる数)くらいをまとめてコンパイルすると普通に数分かかったりするので、この最適化をどのタイミングでどう実現するかは全く自明でない。
その戦略を考えるのが結構大変だったので、RubyKaigiの時点では定期的にまとめてコンパイルするだけのスレッドを新たに立てるつもりだったが、実装が複雑になるのでMJIT用のワーカースレッドは増やさないことにした。
その上で、短期間に少量のメソッドをコンパイルするOptcarrotでのパフォーマンスを維持しながら、数分かけて大量のメソッドをコンパイルするRailsでの性能を改善するため、以下の要素を考慮して設計することにした。
- 初めてコンパイル+ロードされるまでの時間
- soをまとめた後コンパイル済メソッドそれぞれのためにdlsym + ロックを取って生成コードを差し替える時間
- 生成コードの数が溢れた時にメインスレッドで生成コードをdlcloseする時間
- まとまったsoのコードに差し替えられるまでの時間
- メモリ使用量
- Ruby実行中 /tmp に持ち続けるファイルの数とサイズ
より上にある奴がより優先度が高く、下の方は(どうせ大した量使わないのもあり)どうでもいいと思っている。
最終的な構成

上記の1のためにワーカーはメソッドを1つずつコンパイルし、4のためにそのコンパイル結果の.oを /tmp に残し続けることにし、一方で一つ.oが増える度に一つのsoにしてロードし直してると2が線形に重くなって厳しいので4は多少犠牲にして一定回数おきにだけまとめてロードすることにして、そうするとある程度3や5が小さくて済み、6に関してはどうにかしたくなったら複数の.oファイル達を1つの.oにまとめれば良いだろう、という方針で作り始めた。
で、速度に関してはその方針でいいとして、メモリ使用量を考慮すると上記の図の"Sometimes"にあたる頻度がちょっと難しい。現状の実装では、呼び出されている最中の生成コードをそのフレームの外からVM実行に置き換えるOSR*3を実装できていないので、あるタイミングで1つの.soにまとめて生成したコードがどのフレームで使われているかを新たに管理するようにしないと、使われなくなったコードの破棄*4ができないのだが、それをやるとコードが結構複雑になる上に結局メモリ使用量も増えてしまう問題があり、あまりやりたくない。
それをサボる場合、頻度を上げれば上げるほどメモリリーク的な挙動になる*5わけなので、とりあえず キューイングされた全てのメソッドがコンパイルされた時 か --jit-max-cacheに達した時 だけ一つの.soにまとめてロードする処理をやる状態でコミットした。
OSRは他の最適化にどの道必要なので、長期的にはOSRを実装して任意のタイミングで古い生成コードを全て破棄できる状態にしようと思っている。
ベンチマーク
チケットの報告に使われているDiscourseというRailsアプリの、ウォームアップ*6後の GET / リクエスト100回で、以下のものを計測した。
- trunk: r64082
- trunk JIT: r64082 w/ --jit
- single-so JIT: r64082 + 今回のパッチ w/ --jit
- objfcn JIT: shinhさんのobjfcnをr64082からrebaseしたもの
レスポンスタイム(ms)
| trunk | trunk JIT | single-so JIT | objfcn JIT | |
|---|---|---|---|---|
| 50%ile | 38 | 45 | 41 | 43 |
| 66%ile | 39 | 50 | 44 | 44 |
| 75%ile | 47 | 51 | 46 | 45 |
| 80%ile | 49 | 52 | 47 | 47 |
| 90%ile | 50 | 63 | 50 | 52 |
| 95%ile | 60 | 79 | 52 | 55 |
| 98%ile | 91 | 114 | 91 | 91 |
| 100%ile | 97 | 133 | 96 | 99 |
速度増加の割合
小さい値の方が良く、 太字 が速くなっている箇所。
| trunk | trunk JIT | single-so JIT | objfcn JIT | |
|---|---|---|---|---|
| 50%ile | 1.00x | 1.18x | 1.08x | 1.13x |
| 66%ile | 1.00x | 1.28x | 1.13x | 1.13x |
| 75%ile | 1.00x | 1.09x | 0.98x | 0.96x |
| 80%ile | 1.00x | 1.06x | 0.96x | 0.96x |
| 90%ile | 1.00x | 1.26x | 1.00x | 1.04x |
| 95%ile | 1.00x | 1.32x | 0.87x | 0.92x |
| 98%ile | 1.00x | 1.25x | 1.00x | 1.00x |
| 100%ile | 1.00x | 1.37x | 0.99x | 1.02x |
50%ileと60%ileは微妙だが、1000リクエストする計測でやり直すと50%ileや60%ileのtrunkとの差が1msとかだけになる*7ので、微妙に遅くなるか運が良いとちょっと速いという状態まで改善した。
感想
objfcnに比べ遜色ない効果が出せているし、Optcarrotも仕組み上今回の変更ではベンチマーク結果に影響はないので、生成コードのメモリ局所性の問題に関してはうまく解決できたと思う。Railsで遅くはならない状態にできたので、今度は速くしていくのをがんばりたい。
*2:メソッドごとに実際に2MB使われているわけではないことに関する詳細はshinhさんがブログで解説しています http://shinh.hatenablog.com/entry/2018/06/10/235314
*3:On-Stack Replacement
*4:対応するハンドルのdlclose
*5:というかこれの対策は今入ってないわけだけど、まあ2.6のリリースにOSRが間に合わなそうなら適当な回数で.soをまとめる処理をやめるようにしようと思っている
*6:詳細は https://github.com/ruby/ruby/pull/1921 を参照
*7:最初からそうやって計測すればいいのだけど、一応起票されたチケットのやり方に合わせた
個人で運用するKubernetesクラスタ
Kubernetesの使用感に興味があってaws-workshop-for-kubernetesというのを先週やり、ちょうどEKSがGAになった直後だったのでEKSが試せたのだけど、まあ最初からマネージドだとあまり面白みがないし金もかかるので、個人のVPSで動かしてた奴を全部Kubernetes上で動かすようにしてみている。
まだ本番で運用した知見みたいなのが貯まってるわけではないのだが、公式のドキュメントを中心に読んでいても単に動かし始める段階で結構ハマって時間を消費したので、これから同じようなことをやろうとしている人向けに備忘録を兼ねて使用感や知見をまとめておくことにした。
Kubernetesは今でもalphaやbetaの機能が多く、今後この記事の内容も古くなることが予想されるので、なるべく公式のドキュメントへのリンクを置くのを意識して書いてある。
構成
現時点で、ConoHaで借りたサーバー (1GB 2コア x 2, 512MB 1コア x 1) で以下のような構成のものを動かしている。

Kubernetes周りの細かい用語は以降で説明するが、要は以下の5種類のものがKubernetesからDockerでデプロイされている。
- Reverse Proxy: nginx-ingress-controller
- Application Server: Rails
- Worker: 非同期ジョブワーカー, Chatbot
- Database: MySQL
- Cron Job: TLSサーバー証明書更新
コスト
このキャパシティだとメモリもCPUも割と余裕がない感じなのだが、落ちても困らない純粋な趣味*1で立てている赤字サーバーなので意図的に最小限のコストで走らせている*2。
Ubuntu 16.04→Ubuntu 18.04に式年遷宮しておこうと思った関係で今回ついでにVPSも乗り換えていて、 雑に調べた中だとConoHaのメモリ1GBプランがメモリ/円, CPUコア数/円で見て最もコスパが良さそうなのでなるべくこれを並べることにしているが、元のVPSの費用が安かったので1台はケチって512MBのプランにしている。
もともとは1年課金で初期費用4000円 + 月2380円のVPS(4コア, 4GB RAM)で動かしていたのが、1時間課金で初期費用0円 + 合計月2430円になったので、コストはほとんど変わっていない。 試験的にDBもKubernetes上で動かしてみたけど、あとで月630円のサーバーを潰して月500円のDBサーバーに移そうと思ってるので最終的には安くなると思う。
お仕事ならクラスタを保守・運用する人件費の方が余裕で高くつくと思うのでEKSのFargate起動タイプが出るまでは大体GKEを選ぶのが良いのだろうと思っているが、真面目には調べていない。
Kubernetesクラスタの作成方法
AWSやGCEで立てるならkopsとかを使うのが普通なのだと思うが、まあその辺のVPSではそういうのは使えなさそうなのでいくつかのツールを検証した。最終的にkubeadmに落ちついたのだが、それ以外を選択しなかった理由についても書いておく。
conjure-up
https://kubernetes.io/docs/getting-started-guides/ubuntu/
上記のUbuntu向けのGetting Startedで使われている通り、多分Ubuntuではconjure-upで立てるのが公式のお勧めなのだろう。ターミナル全体を支配する感じのウィザードが立ち上がり、いくつか選択肢を選ぶだけでセットアップできる。
僕が使った時は普通にsnapでconjure-upを入れたところバグにヒットしたがこれはchannelをedgeにしたら直った。が、これはkubeadmと違ってDocker以外にKVM等の仮想化レイヤーも挟まることになっていて、conjure-upでmaster nodeをセットアップするとConoHaの3コア2GBのマシンでもリソースを使い尽くして死に、その1つ上の4GBのマシンはちょっと高くなってしまうので採用を見送った。
minikube
https://kubernetes.io/docs/setup/minikube/
これもVirtualBox等の仮想化ドライバの上でKubernetesが立ち上がる奴なのだが、使いやすくてよくできている。 手元で開発用に立ち上げるツールとしてはこれが一番いいのではなかろうか。
minikubeを使うためにはVT-xかAMD-vの有効化が必要で、手元のマシンではBIOSで有効にできたがConoHaでは無効だったのでこれも今回は採用できなかった。
kubeadm
https://kubernetes.io/docs/setup/independent/create-cluster-kubeadm/
kubeadmでKubernetesをセットアップすると、master nodeとworker nodeの両方でシングルバイナリのkubeletがsystemd等からホストで直に起動され、kube-apiserver, kube-controller-manager, kube-dns, kube-proxy等その他のコンポーネントはホストのdockerdにぶら下がる形で動く。
そのため余計なオーバーヘッドが少なめで、実際ConoHaのメモリ1GB 2コアのマシンでmaster nodeが割と安定して稼動してくれる。512MB 1コアのマシンだとkubeadm initでCPU使用率が爆発してセットアップが完了しないので、masterはそれ以上ケチることはできない。kubeadm joinするだけのworker nodeは上述の通り512MB 1コアのマシンでも動く。
kubeadm initでmaster nodeを立ち上げた後kubeadm resetで全て綺麗にできるので、色々いじりすぎて何かよくわからないけど動かない状態になってしまって最初からやり直したいという時に、マシンを作り直さなくてもkubeadm resetするだけで良かったのが便利だった。ただしmulti-masterに対応してないのが欠点っぽい。
kubeadmをmitamaeから叩く形でmaster nodeのセットアップは完全に自動化しているが、worker nodeに関してはkubeadm joinする部分だけ一時的なトークンが必要な都合自動化を保留している。
名前解決ができない問題
そもそも僕は最初にkubeadmを試していて、何故conjure-upやminikubeも触るはめになったのかというと、kubeadmでKubernetesクラスタを立ち上げると、何故かkube-dnsで外部のサービス(*.cluster.localとかじゃなくて例えばslack.com等)の名前解決ができなかったためである。
そのためにPodのネットワークアドオンもCalico, Canal, Flannel, Weave Netなど色々試し、最終的にkubeadmなしでmaster nodeをセットアップするのも挑戦することになった(死ぬほど面倒なのでやめた)。ConoHaのファイアウォールも疑ったけど手元の開発マシン(Ubuntu 18.04)でも再現した。minikubeではこの問題はなかった。
で、何日かハマった後、Customizing DNS Serviceというドキュメントをを参考に以下のようなConfigMapを作りkubectl applyすることでこの問題は解決した。upstreamNameserversの実際の値はConoHaコントロールパネルでDNSサーバー1, 2にあったものを使用している。
apiVersion: v1 kind: ConfigMap metadata: name: kube-dns namespace: kube-system data: upstreamNameservers: | ["XXX.XXX.XXX.XXX", "YYY.YYY.YYY.YYY"]
何故kubeadmだとこのような問題が起きるのかはまだちゃんと調べていないが、 *3 内部DNSもちゃんと名前解決できているし今のところ特に困ってはいない。
各コンポーネントの動かし方
冒頭の分類別に、どうやって動かしているかを僕が実際に古いVPSから移してきた順に解説していく。 実際のYAMLをこの記事と一緒に読みやすいように名前等を変えたものを以下の場所に置いておいた。
https://github.com/k0kubun/misc/tree/kubernetes
あくまで参考用で、いくつかはsecretやnodeSelectorの都合そのままkubectl applyしても恐らく動かないことに注意されたい。
各見出しの先頭に、一番参考になると思われるドキュメントへのリンクを貼っておく。どう考えてもそっちを読んでもらった方がいいので、ここでは要点しか解説しない。
Worker
https://kubernetes.io/docs/tasks/run-application/run-stateless-application-deployment/
最初に練習用にRuby製のChatbotであるRubotyをSlack向けに立てた。 最近開発しているRuby 2.6.0-preview2のJITコンパイラで動かしているため、ネイティブコードで高速にレスポンスが返ってくる。

Railsアプリからの非同期ジョブを受けるワーカーも同じ方法で立てられる。 この類のアプリケーションはデプロイ時にダウンタイムがあってもそれほど困らないので、難易度が低い。
単にPodを作るだけでもデプロイは可能だが、Deploymentリソースを作ってそいつにPodを作らせることで、 OOMとかで殺されても再度勝手にPodが作られるようにすることができる。それ以外それほど考えることはなさそう。
別途Vaultとかを設定しなくとも、Secretリソースでetcdに保存しておいた秘匿値を参照できる。 ワーカーのYAMLの方に例を書いてあるが、他の平文と環境変数と並べて書けて便利。
また、次に解説するMySQLへは、"default"ネームスペースに"mysql"という名前のServiceを作っておくことで、mysql.default.svc.cluster.localという名前でアクセスできる。
Database
https://kubernetes.io/docs/tasks/run-application/run-single-instance-stateful-application/
https://kubernetes.io/docs/tasks/run-application/run-replicated-stateful-application/
上記は2つともMySQLの例だが、CassandraとかZooKeeperの例もドキュメントにあり、状態を持つアプリのデプロイもPersistentVolumeやStatefulSetsなどにより割と手厚いサポートがある。
まあ、普通の神経してたらDBはRDSとか使うのが普通だし、マルチテナントなコンテナクラスタに状態のあるアプリをデプロイしても実際はあまり嬉しくないと思うが、一応以下のようなYAMLでできる。
ホストの適当なパスを選んでPersistentVolumeというリソースを作っておくと、PersistentVolumeClaimというリソース経由でPodにボリュームをアタッチしてコンテナにマウントできる。 そのボリュームでのディスク使用量に制限をかけられるのが便利なところだと思う。 *4 MySQLの場合/var/lib/mysqlがコンテナを停止してもホストに残るようにしておけば良い。
Reverse Proxy
https://kubernetes.github.io/ingress-nginx/deploy/
https://kubernetes.io/docs/concepts/services-networking/ingress/
Serviceというリソースでも外部へのサービスの公開は可能だが、僕の場合はTLS terminationをやるためにIngressリソースを使う必要があった。 しかし、Ingressというのは"ingress controller"というのを設定しないと動いてくれないという特殊なリソースで、Serviceと違ってkube-proxy先輩は面倒を見てくれない。
例えばAWSだとALBをバックエンドにしたIngress Controllerを使うことになると思うが、その辺のVPSで立てるならnginx-ingress-controller等を使う必要がある。nginx-ingress-controllerの設定で結構ハマってなかなかパブリックIPからアクセスできる感じにならなかったのだが、最終的に以下のような設定をしたら動いた。
ホスト名とかがヒットしなかった時に使われる--default-backend-serviceは指定しないと起動に失敗する。
またKubernetesでRBAC(Roll-based access control)が有効になっているとnginx ingress controllerは様々な権限を要求してくるので、がんばって権限管理をする必要がある。RBACには権限のリソースにRoleとClusterRoleの2つがあり、それぞれRoleBindingとClusterRoleBindingによってnginx-ingress-controllerのPodのServiceAccountに紐付ける必要がある。
Podのspec.serviceAccountNameでServiceAccountは指定可能だが、デフォルトでは"default"というServiceAccountに紐付いていて、上記の例ではそいつに何でもできるcluster-adminというClusterRoleを紐付けている。良い子は真似しないように。
Application Server
https://kubernetes.io/docs/concepts/services-networking/service/
Ingressから参照するServiceリソースを立てておく必要があるところがWorkerと異なるが、他は基本的に同じ。
静的ファイルの配信はnginxとかに任せるのが定石だけど、まあ設定が面倒になるのでこの例ではRAILS_SERVE_STATIC_FILES環境変数をセットしてRailsにアセットの配信をやらせている。どうせクライアント側でキャッシュが効くのでカジュアルな用途ではこれでいいと思うが、真面目にやるならS3にアセットを上げておいてCDNから参照させるようにするとかがんばる必要がある。
Cron Job
https://kubernetes.io/docs/concepts/workloads/controllers/cron-jobs/
CronJobというリソースでJobリソースを定期実行できる。Kubernetes 1.4だとScheduledJobという名前だったらしい。
僕はこれでLet's EncryptのTLSサーバー証明書の更新をやっている。公式のcertbotはPythonなのが気にいらないのでRuby製のacmesmithというのを使っていて、これもJITを有効にしているため高速に証明書が更新できる*5。
無駄に毎日叩くようにしてあるが、証明書が新しければacmesmith側で更新がスキップされるようになっているので特に問題はない。
実際の更新スクリプトが何をやるかはこのYAMLからは読み取れないようになっているが、curlでhttps://${k8s_host}/api/v1/namespaces/default/secretsにPOSTしてnginx-ingress-controllerが参照しているSecretリソースを更新している。-H "Authorization: Bearer ${x8s_token}"もつけないとUnauthorizedになるが、このトークンの取得方法はこのYAMLのコメントにあるコマンドで見ることができる。
動かしてみてわかったこと
master nodeのエージェントが結構メモリを使う
master nodeにPodをスケジューリングするのはsecurity reasonsのためデフォルトで無効になっているが、まあコストのためにmaster nodeのリソースも普通に使うつもりでいた。
しかしKubernetesのmaster nodeに必要なプロセス達は結構なメモリを使ってしまうので、そのアテは外れた。特にkube-apiserverはメモリ1GBのマシンでコンスタントに25%くらいメモリを使うし、etcd, kube-controller-manager, kubeletもそれぞれ5%くらい使うし、他にも1%くらい使う奴がいっぱいある。設定でどうにかできるなら是非改善したい。
メモリ1GB 2コアのmaster nodeにChatbotを立てるくらいは流石にできたけど、master nodeの余剰リソースにはほとんど期待しない方がいい。 調子に乗ってmaster nodeのリソースを使い切るとkubectlが使えなくなってPodの停止もできなくなるので、マシンの強制終了くらいしかできなくなってしまう。それがsecurity reasonsなのかもしれない。
ちなみにworker nodeでもkubeletやdockerdが動いているため、worker node側も限界までリソースが使えるとは考えない方が良いと思う。
ある程度余裕を持ってキャパシティを見積る必要がある
割と当たり前の話だが、コンテナクラスタに余剰リソースがないと、rolling updateで新しいイメージをデプロイしようとした時に新たなPodのスケジューリングに失敗する。master nodeのリソース使用量が予想外に大きかったので結構ギリギリで今運用してるのだけど、停止時間を作りたくないデプロイをする時に普通に困る*6。
Kubernetesの前身であるBorgの論文だと、バッチジョブとかのプライオリティを下げておき、よりプライオリティが高いタスクのスケーリングの際にそれを犠牲にする(Resource ReclamationやPreemptionと書かれている)運用戦略が語られているが、KubernetesにもPod Priority and Preemptionが存在するので、バッチジョブがある程度ある場合はそいつに融通を効かせるというのもできるかもしれないが、まだ試してない。
感想
普通はDockerコンテナ用意してちょろっとYAML書くだけでデプロイできる基盤があったら便利だけど、この規模の用途で使うなら、master nodeの運用の面倒さとかKubernetesがやたらリソースを食ってくるデメリットの方が高くつきそうなので、アプリはホストに普通に立ててリソース制限はsystemdとかでやるのがいいと思う。
*1:このRailsアプリは自作テンプレートエンジンや自作JITコンパイラに加えGraphQLやReactやwebpackerが使われていたり、RubyじゃなくてわざわざJavaでワーカーを書いたりと、色々好き放題やるために立てている。
*2:落ちても困らないのでkubeadmの推奨スペックを下回るマシンを使っている。Rubyを--with-jemallocでビルドし、UnicornをやめてPumaをスレッドベースで走らせることでメモリ使用量を抑えるみたいなこともやっている。
*3:Ubuntu固有の問題のようです https://inajob.hatenablog.jp/entry/2018/02/28/%E6%9C%8810%E3%83%89%E3%83%AB%E3%81%A7%E6%B5%B7%E5%A4%96VPS%E3%81%A7Kubernetes%E3%82%92%E8%A9%A6%E3%81%97%E3%81%A6%E3%81%BF%E3%82%8B%EF%BC%88kubernetes_v1.9%E7%89%88%EF%BC%89
*4:@nekop さんに訂正いただきましたが、hostPathではランタイムでQuotaの制限はないそうです https://twitter.com/i/web/status/1010037274694770688
*5:まあ当然これは冗談で、長い間走らせ続けるChatbotに比べたらむしろ実際には遅くなるくらいだと思われる
Ruby 2.6にJITコンパイラをマージしました
The English version of this article is available here: medium.com
2/4(日)に、去年のRubyKaigiが終わった直後の新幹線で開発を始め10月に公開したJITコンパイラをRubyのtrunk (2.6.0-dev) にマージし、昨日TD Tech Talk 2018で以下のような内容の発表をしました。
まだそれほど速くできていないということもあり、私はTwitterでのみ共有して満足していたのですが、海外の方がいくつか記事を書いてくださいました。
とても丁寧に書かれているので、私の記事がわかりにくければそちらもどうぞ。ただ、いくつか補足したい点があったのと、また昨日の発表内でうまいこと説明できなかった点があるので、そのあたりに触れつつ今回マージしたJITコンパイラについての概要を記事にしようと思います。
"MJIT"とは何か
この見出しの内容はある程度知ってる方がいる気がするので、僕のYARV-MJITの話を聞いたことがある人は「RubyのJITの現状」まで飛ばしてください。昨日の僕の発表を聞いてくださった方は、発表時に話せなかった「JITコンパイラの自動生成の裏側」まで飛ばしてください。
ここでは、RubyのJITにまつわる最新の動向をダイジェストでお伝えします。
RubyのVMのRTL命令化プロジェクト
これは2016年7月の話なのですが、Ruby 2.4でHashを高速化 (Feature #12142)したVladmir Makarovさん(以下Vlad)が、VM performance improvement proposal (Feature #12589)というチケットを作りました。
タイトルの通りVMのパフォーマンスを上げる目的の提案なのですが、RubyのVMがJava等と同じくスタックベースの命令で作られてるのに対し、その命令を全てレジスタベースのもの(以下RTL: Register Transfer Language)に置き換えようという内容になっています。
VladはGCCのレジスタアロケータの作者であり、インストラクションスケジューラのメンテナでもあります。そのGCCは内部でレジスタベースの中間表現を使っているため、そこで得たノウハウを適用して高速化しようという目論みだったのでしょう。
全ての命令を書き変えるような大きな変更にも関わらず、make testが通る完成度のRTL命令の実装が公開されました。純粋なレジスタベースへの置き換えだけでなく、実行時にレシーバや引数のクラスに応じてバイトコードを動的に書き変える仕組みを用意して、クラスに応じた特化命令が使われるようにする変更も入っています。
一方この変更だけでは、一部のマイクロベンチマークではパフォーマンスが向上したものの、Optcarrotのようなある程度規模の大きいベンチマークではパフォーマンスが劣化してしまう状態でした。
RTL命令上で動くJITコンパイラMJIT
そのような問題を解決するため、2017年3月末、RTL命令をベースに動作するMJIT (MRI JIT)というJITコンパイラの実装が公開されました。
rtl_mjit_branchのページにRubyのJITのための方針がいくつか検討されていますが、採用されたのはCのコードを生成してディスクに書き出し、Cのコンパイラを実行してそれをコンパイルしロードするというものでした。

RTL化の際にインライン化に有利な命令列が動的に生成されるようになっており、そのコードをJITすると、先ほどのOptcarrotでもかなり高速(Ruby 2.0の2〜3倍)に動作するようになりました。
一方で、VMの実装を大きく書き換えた副作用として、make testは通るもののmake test-all等のよりシビアなテストはJIT有効/無効に関わらず通らない状態になってしまい、Optcarrotもベンチマークモードでしか起動可能でなかったり、Railsも起動に失敗する状態でした。
YARV-MJITとは
このようにRTL命令化はある程度リスクのある変更だったのですが、私の会社ではクラウドサービスをRailsアプリケーションとして実装して提供しておりとても高い可用性が求められるため、想定外のバグが発覚するリスクの高い変更がRubyに行なわれてしまうと、バージョンアップがとても大変になるだろうという懸念がありました。
RubyKaigiでのVladの発表の後、私はどうにかしてリスクを軽減しながらRubyにJITを導入できないか考えました。そこで思いついたのがYARV-MJITと私が呼んでいるアプローチで、MJITのJIT基盤をそのまま使いながら、RTL命令ではなく現在のスタックベースのYARV命令をベースにJITコンパイルを行なうというものでした。
このJITのアプローチはVMの実装を全く変えずに実現できるため、リリース後JITコンパイラにバグが発覚しても、JITコンパイラを無効にしてしまえばRubyが今まで通り動作することがほぼ確実となります。
リスクを抑えるためVMの命令セットに変更を加えないという制約をかけていたのもありMJITほどのパフォーマンスは出せなかったのですが、公開後様々な改善を減てYARV-MJITでもある程度MJITに近い速度が出るようになりました。
いくつかの未熟な最適化を取り除くと、YARV-MJITはある程度の速度を保ちながらもJIT有効な状態でRubyのテストが全て通るようになったため、2017年末にMJITのJIT基盤とYARV-MJITのマージを提案し、ポテンシャルバグやランダムなクラッシュの修正の後、2018年2月に無事マージされました。
RubyのJITの現状
Ruby 2.6に向けて今回マージされたのは主に以下の2つのコンポーネントに分けられます。
VladのMJITはもともとJITコンパイラ部分も含めた呼称と考えられるため、そのうちJITの基盤となる部分のことを私はチケットやコミットメッセージ上ではMJIT Infrastructureと区別して呼んでいます。
が、たくさん名前を覚えるのは面倒ですし、ユーザーの皆さんからしたら中の実装に何が採用されたとかはどうでもいいかもしれないので、両方合わせてMJITと呼んでいただくのは別に構わないと思います。
これは昨日TD Tech Talk 2018で話した内容なのですが、現状それぞれどこまで実装が進んでいるのかという点について共有します。
JITコンパイラについて
ベンチマーク
パフォーマンス改善のための変更なので、いくらリリースのリスクを抑える目的があるとはいえ、当然パフォーマンスが向上しなければ導入するべきではないでしょう。なので、私のマシン(Intel 4.0GHz i7-4790K 8 Cores, 16GB memory, x86_64 Linux)でのベンチマーク結果をいくつか載せておきます。
Optcarrot

これは最新のOptcarrotベンチマークの結果です。YARV-MJITも一時期68fpsくらい出ていたんですが、そこからいくつか不完全な最適化を取り除いているためこのようなパフォーマンスになっています。
JITのマージのPull Requestでは最初63fpsのベンチマークを貼っていて、Squareさんの記事でもこれを引用されているように見えるのですが、そこから更に最適化を1つ一時的に外しているため、PRの本文に書いてあるようにマージの段階でベンチマーク結果が変わって58fpsになっています。マージ後r62388で59fpsくらいになりましたが、63fpsに届くために必要な最適化*1はまだ外したままです。そのうち直します。
RubyBenchの更新が最近止まっているため正確にどの変更の影響が大きいのか調べるのが難しい状況*2なのですが、最近shyouheiさんがVMで様々な改善を行なっている*3ためか、Ruby 2.6では実はJIT無しでもOptcarrotベンチマークは結構速くなっています。
JITがそれほどパフォーマンスに影響を与えられていないというのは私個人にとっては少し残念な話ですが、Ruby 2.6がJITなしでも速くなっているというのは良いニュースでしょう。
Benchmark in "Playing with ruby's new JIT"
VM実行に比べ現時点のJITの高速化の可能性は本当に上記のように数パーセントしかないのでしょうか?
Playing with ruby's new JIT: MJITの記事にはベンチマークスクリプトがあり、それをtrufflerubyの人が改良したものが以下のようなものになっています。
def calculate(a, b, n = 40_000_000) i = 0 c = 0 while i < n a = a * 16807 % 2147483647 b = b * 48271 % 2147483647 c += 1 if (a & 0xffff) == (b & 0xffff) i += 1 end c end benchmark.ips do |x| x.iterations = 3 x.report("calculate") do |times| calculate(65, 8921, 100_000) end end
これを私のマシンでも実行してみました。
$ ruby -v
ruby 2.6.0dev (2018-02-15 trunk 62410) [x86_64-linux]
$ ruby bench.rb
Warming up --------------------------------------
calculate 13.000 i/100ms
calculate 13.000 i/100ms
calculate 13.000 i/100ms
Calculating -------------------------------------
calculate 1.800k (± 2.7%) i/s - 8.996k in 5.002504s
calculate 1.785k (± 7.4%) i/s - 8.853k in 5.003616s
calculate 1.802k (± 4.0%) i/s - 8.996k in 5.006199s
$ ruby --jit bench.rb
Warming up --------------------------------------
calculate 13.000 i/100ms
calculate 18.000 i/100ms
calculate 27.000 i/100ms
Calculating -------------------------------------
calculate 7.182k (± 9.1%) i/s - 35.397k in 5.000332s
calculate 7.296k (± 2.9%) i/s - 36.450k in 5.001392s
calculate 7.295k (± 3.1%) i/s - 36.450k in 5.002572s
1.802k → 7.296k ですから、大体4.0倍くらいですかね。Ruby 3x3達成しましたね。
これは多分JITの宣伝のために作られたような架空のワークロードだと思いますが、正しく現実世界の用途に向けJITをチューニングしていけば、現在の最適化戦略で大きな改善ができる可能性を示唆していると思います。
またこのベンチマークに関しても、手元のtrufflerubyで動かしたところ667.854k (trunkのVM実行の約370倍)になったので、我々もこのような最適化しやすいケースに関しては数百倍のオーダーを目指すべきだと認識しています。
その他のベンチマーク
JITコンパイラをマージした時のコミットのコミットメッセージに、Optcarrot以外にもマイクロベンチマークの結果(JIT offの状態に比べ2倍程度速くなっているのがいくつかあります)と、Railsでのベンチマーク結果を載せています。
Railsのベンチマークに関してはNoah Gibbsさんのrails_ruby_benchを使用したいところなのですが、私の手元で動かない状態になっているので、それが直せるまでは現状そのベースとなっているdiscourseリポジトリのベンチマークを使用しています。
そのRailsのベンチマークだと速くなるどころか若干遅くなってしまうというのが現状であり、原因はまだ調査中なのですが、Sam SaffronさんがUnicornはforkするので子プロセスでJITが有効になっていないのではという指摘をされていて、実際無効にしているので、このあたり直しつつ遅くなっている原因の切り分けもやっていこうとしている状態です。
JITコンパイラの自動生成
JITコンパイラはVMと同じ挙動をしなければいけないため、素朴に実装するとJITコンパイラはVMの実装のコピペが多くなり、保守性が下がってしまいます。
RubyのVMはもともとinsns.defという特殊なテンプレートフォーマットをパースしてVMを生成するERBに渡すことで生成されているのですが、insns.defからJITコンパイラも生成するようにできないかという提案をささださんからいただき、やってみたところ上手くいきました。
以下のようなmjit_compile.inc.erbというファイル(わかりやすいようにいろいろ省略)があり、
switch (insn) {
% (RubyVM::BareInstructions.to_a + RubyVM::OperandsUnifications.to_a).each do |insn|
case BIN(<%= insn.name %>):
<%= render 'mjit_compile_insn', locals: { insn: insn } -%>
break;
% end
}
命令に応じてswitch-caseで分岐しながら、_mjit_compile_insn_body.erbというファイルでinsns.defの中身をfprintfするコードを生成しています。
% expand_simple_macros.call(insn.expr.expr).each_line do |line| % if line =~ /\A\s+JUMP\((?<dest>[^)]+)\);\s+\z/ /* JUMPの動的生成コード */ % else fprintf(f, <%= to_cstr.call(line) %>); % end % end
マクロをJIT向けに事前に変換し、またJUMP命令は特にcase-when文に関して簡単な変換が難しいため動的に生成するようになっています。それ以外のコードは基本的にはfprintfの羅列で、このmjit_compile.inc.erbからは以下のようなファイルが生成されます。
switch (insn) { case BIN(nop): fprintf(f, "{\n"); { fprintf(f, " reg_cfp->pc = original_body_iseq + %d;\n", pos); fprintf(f, " reg_cfp->sp = (VALUE *)reg_cfp->bp + %d;\n", b->stack_size + 1); fprintf(f, " {\n"); fprintf(f, " /* none */\n"); fprintf(f, " }\n"); b->stack_size += attr_sp_inc_nop(); } fprintf(f, "}\n"); break; case BIN(getlocal): /* ... */ }
上記はMJITのワーカースレッドとして実行され、実行時に以下のようなコードをファイルに書き出します。
VALUE
_mjit0(rb_execution_context_t *ec, rb_control_frame_t *reg_cfp)
{
VALUE *stack = reg_cfp->sp;
static const VALUE *const original_body_iseq = (VALUE *)0x5643d9a852a0;
if (reg_cfp->pc != original_body_iseq) {
return Qundef;
}
label_0: /* nop */
{
reg_cfp->pc = original_body_iseq + 1;
reg_cfp->sp = (VALUE *)reg_cfp->bp + 2;
{
/* none */
}
}
/* ... */
} /* end of _mjit0 */
rb_execution_context_tというのはスレッドのようなもので、rb_control_frame_tがコールスタックのうちの1つのフレームを表しているので、あるスレッドのあるフレームで実行できるようなインターフェースになっています。
このファイルをコンパイルしてdlopen, dlsymするとこれの関数ポインタが得られるので、そのポインタが既に存在したらVM実行のかわりにこれを呼び出すことでJIT実行が実現されます。
JITコンパイラの自動生成の裏側
ささださんくらいしか興味がないような気もするのですが、この自動生成のために必要だったことを紹介します。
次のメソッド呼び出し処理のマクロ定義分岐
RubyのVMを1つ起動するとsetjmpという重い処理をする上マシンスタックを大きく消費するため、あまり何度も起動したくありません。従ってRubyのVMは、Rubyのコードだけを処理している間は別のVMを起動せず使い回すように作られています。
これがRESTORE_REGS();,NEXT_INSN();という2つのマクロで実現されていたのですが、マクロが2つに分かれていると変換もしづらくとても都合が悪いため、これらをまとめて実行するEXEC_EC_CFP()というマクロを勝手に作り、JITの関数内ではそれがvm_exec()というVMを起動する関数を実行するようになっています。書いてて思ったけどここで先にmjit_exec()するようにした方が速いような。
vm_exec.h内で、MJIT_HEADERというマクロが定義されていたらマクロの定義自体が変わるように実装されています。
例外命令のマクロ定義分岐
Rubyの例外は基本的にはlongjmpを呼び出し大域脱出することで実現されているのですが、それがまあとても遅い処理なわけで、Rubyが内部実装の都合で使っているthrow命令は単にVM実行の関数(vm_exec_core)からreturnして、その関数をラップしている関数(vm_exec)で大域脱出先のISeqを線形に探索して実行する、というような実装になっています。
当然このコードはvm_execにラップされていないと動かないのですが、先ほどいったようにこいつはsetjmpするのでそれも呼びたくなく、基本的にmjit_execはvm_execを経由せず呼び出しているため、throw命令に使われているTHROW_EXCEPTION()というマクロを、単にreturnするのではなくlongjmpするように変更しています。
これもvm_exec.h内で分岐しています。
例外ハンドラーからのISeq実行の無視
vm_execにラップされてないと動かないのと同じ問題が他の場所にもあり、vm_exec内の例外ハンドラからISeqの実行が始まる場合setjmpの実行がスキップされておりこれも動かないので、その場合そのISeqはJITで実行されないようになっています。
opt_case_dispatchの動的コンパイル
case-whenってありますよね。opt_case_dispatchのオペランドにHashが入っていて、キーが単純で高速に分岐できる場合はそこからテーブル引きで分岐先のアドレスが取得されるようになっています。
で、それはVMの実装向けにgotoが走るようになっていてそのままでは動かないので、JITの実装向けにJITの関数内でのラベルにgoto先を変換しています。
これにはそのHashの中身を見る必要があり、これを見るためにHashの操作を行なう関数を使っていたらランダムにSEGVしていた(GVLのコントロールから外れているMJITのスレッドでRubyのVMを利用すると、当然同時にメインのスレッドでも使っているので壊れてしまう)ので、Hashからstを取り出し、stを操作する関数を使うようにしています。
プログラムカウンターの移動
これはRubyのメソッドJITコンパイラの実装初心者(誰)がハマりがちな罠なのですが、一見不要そうに見えるプログラムカウンターの移動をサボると、突然例外で大域脱出した時に実行するべきISeqのlookupが意図通りではなくなってしまいます。なので、全ての命令の実行時に毎回プログラムカウンターを動かす必要があります。
スタックポインターの移動
もともとYARV-MJITはVMのスタック操作相当のものをJITされた関数のローカル変数上で行なうようになっており、それによってそのJITされた関数内でのスタック操作が他の関数から影響を受けないことを保証してコンパイラに最適化させるという意図を持っていました。値を適切なローカル変数に代入してVMのスタックの挙動を再現するため、JITコンパイル時にスタックのサイズを計算するコードが入っており、スタックポインタ相当の計算をコンパイル時に終わらせることができるようになっています。
が、これだと例外で大域脱出した瞬間そのローカル変数の値が失われてしまうという問題がありました。そのため、この速さを維持するためにはlongjmp前にlongjmpで失われる全てのフレームのローカル変数をそのフレームの外側から退避する必要がありました。
それの実装がまだできてないので現在はローカル変数のかわりにVMのスタックを使用しており、スタックポインタも毎回動かさなければならない状態になっており、これが最初のPull Requestの提案から遅くなってしまったポイントです。
この退避の実装を実装するためにローカル変数のアドレスを必ず取る必要が発生するので、もしかするとそのせいでコンパイラが最適化できなくなり、例外が絶対に発生しなさそうなISeqではそれをスキップした方がいいかなあ、とか考えています。
JIT基盤について
プラットフォームの対応状況
MJITのワーカースレッドがpthread直書きだったのを、YARV-MJITの開発中にRubyのスレッドの抽象化レイヤーを使って移植するのはマージ前に終わっていました。
マージ後、MJITのランタイムではなく、JITコンパイル時に使用するヘッダーのビルドが以下のようなプラットフォームで動かなくなるのを報告いただいたり、RubyCIで確認したりしました。
私の手元にはLinux, macOS, MinGW, 新しめのVisual Studioの環境があり、そこで動くことは確認していたのですが、Rubyが要求するポータビリティにはそれでは足りなかったようです。NetBSDやSolarisのVMをインストールしたり、hsbtさんにICCの環境を用意していただいたりしてデバッグし、どうにかビルドが通る状態に持ってきました。
その後、同期的にコンパイルを行なう--jit-waitというオプションを用いてRubyのユニットテストにJITのテストを追加し、gcc+Linuxという環境では基本的に動作しているのですが、clangとMinGWの環境でいくつかRubyCIの失敗が残っていて、これらはこれから修正していこうと思っている状態です。
また、Windows環境に入っているCのヘッダは、コンパイル時間を短縮するための変換をしようとするとエラーになる状態になっており、一旦それをやらないようにしているので、MinGWではJITは一応動いていますがコンパイル時間がかなり長いという問題があります。これはヘッダの変換のバグを直すしかないでしょう。
セキュリティ
JIT基盤に関してはnobuさんやusaさんがいろいろ修正をしてくださっていて、その中でnobuさんがセキュリティの脆弱性についても修正してくださっています。
MJITのワーカースレッドがCのファイルを書き出す時に/tmp/_ruby_mjit_p123u4みたいなファイルをfopenしていたのですが、まずファイルのパーミッションに対するコントロールがなかった(これはnobuさんからの指摘で認識していたのでそのうち直すつもりでマージしていた)のと、既存のファイルに書き始めると任意のパーミッションになってしまうため、ファイルを作成する時もそのパスに既にファイルがないことが保証されるコードになりました。
いまのところそれ以外の脆弱性は確認されていませんが、リリース前に精査する必要がありそうです。現時点で本番環境で試していただくのは、こちらとしては助かるのですが、正式リリースまではある程度自己責任でやっていただく形になってしまいます。
その他の補足
"Startup Time"について
Ruby's New JITには、"Startup Time"というセクションで以下のように説明されています。
Startup time is one thing to take into consideration when considering using the new JIT. Starting up Ruby with the JIT takes about six times (6x) longer.
重要な気付きだと思います。この理由は、--jitがついているとRubyの起動時にJIT用のprecompiled headerのコンパイルを開始し、またRubyの終了時にそのJITワーカースレッドが現在行なっているJITコンパイルが終わるのを待つため、最低でもCのファイル1回分のコンパイル時間がかかってしまいます。コンパイルが遅いコンパイラを使うとこの時間は伸びるわけです。
解決策は以下の2つあります。
プリコンパイルドヘッダは実際にはRubyのビルド時にはプリコンパイルされていません。これはコンパイラのバージョンが途中でアップグレードされプリコンパイルドヘッダのフォーマットが変わってしまうのではないかということを懸念して毎回コンパイルしていることによります。もしサポートしているコンパイラ全てでそのようなことがほとんどないことがわかればそれで良いでしょうが、現在は保守的な方向に倒しているためこうなっています。
JIT用のスレッドを任意の瞬間にキャンセルして、途中で生成されていた全てのファイルを上手いこと特定して削除できる方法があればより速く終了できるのですが、これはあまり安全な方法ではないでしょう。
--jit-ccはなくしました
記事では--jit-cc=gccが使われていたりするのですが、JIT時に使うヘッダの生成に使用したコンパイラ以外のコンパイラをJITに使用すると割と多くのケースで壊れてしまい、それが壊れるのはRubyの責任ではないのでサポートしないことにしています。
--jit-ccは間に合せで残していたオプションなのですが、nobuさんがいろいろ改善してくださって、Rubyのビルドに使われたコンパイラ(JIT用のヘッダの生成にも使われる)をマクロで判定してコンパイラを特定するように変わりました。
従って、普段gccを使っているがclangでのパフォーマンスも確認してみたい、という人はclangでRubyをビルドし直すようにしてください。
謝辞
Ruby 2.6のリリースまで私のJITコンパイラが残っているかはまだわかりませんが(!?)、RubyにJITが入るまでに様々な方に助けていただいたので、ここで以下の方にお礼を申し上げます。
- MJITの基盤を発明したVladimir Makarovさん
- 様々な場所でお世話になっているまつもとさん
- YARV-MJITについて様々な相談に乗っていただいたささださん、mameさん
- マージ前に多くのバグを報告・修正していただいたwanabeさん
- 最初のMinGWサポートを書いたLars Kanisさん
- ビルド環境でいつもお世話になっているhsbtさん
- マージ後基盤の方を直してくださっているnobuさん、usaさん、znzさん、knuさん
- コードを通じてJITコンパイラの生成回りで助けていただいたshyouheiさん
Ruby 2.6.0 preview1 そろそろ出ます
JITが入ったのでpreview1早めに出しませんかみたいな提案があり、成瀬さんがpreview1の準備を始めています。 その時点ではJITはそれほど速くなってないと思いますが、新しいものが好きな方はそこで少し遊んでみていただけると助かります。
2017年にやったこと
要約
今年はクックパッドからTreasure Dataに転職し、Rubyコミッターになり、結婚しました。
近況です / “Treasure Data に入社しました - k0kubun's blog” https://t.co/7G7WMahI6L
— k0kubun (@k0kubun) 2017年3月1日
書きました / “Ruby コミッターになりました - k0kubun's blog” https://t.co/2jkQehfmBc
— k0kubun (@k0kubun) 2017年5月15日
入籍しました
— k0kubun (@k0kubun) 2017年9月1日
発表
今年は7回発表したのですが、9ヵ月くらいJITを触っていたので3回はJITの話になってしまいました。
Cookpad TechConf 2017: 快適な開発環境, CI, デプロイ等の話
前職でやっていた仕事の中でまだ発表していなかった工夫について話しました。2018年は、現職で前職とは少し要件の違うデプロイ環境を整備していくことになっているので、やっていきたいと思います。
TreasureData Tech Talk 201706: TD APIの話とERBの高速化の話
RubyコミッターとしてメンテするようになったERBをRuby 2.5で2倍速くした話とかをしました。
TokyuRuby会議11: Haml 5の高速化の話
Haml 5で内部の設計を結構大きく変え、3倍速くした話をしました。これに起因したバグはいまのところなく、とても上手くいったように思います。
ぎんざRuby会議01: Railsのパフォーマンス改善全般
計測の重要性について語りつつ、今までの発表とは異なる点として、最近バイトコードを読みながら最適化をするようになったのでそのあたりの知見を共有しました。
RubyKaigi 2017: LLVMベースのJITコンパイラ LLRB
今年Ruby向けに2つのJITコンパイラを実装したのですが、その1つ目の話です。LLVMでJITを実装するのは割と素直な方針だと思っていたのですが、やってみると一番必要なのは既にCで書かれたコードをいかにインライン化するかというのが肝になるので、LLVMを生かしきれるステージはまだ先かなあという感じでした。
RubyConf 2017, Rails Developers Meetup 2017: JITコンパイラYARV-MJIT
2つ目のJITコンパイラ。upstreamへのマージ計画 https://bugs.ruby-lang.org/issues/14235 もある本命プロジェクトです。がんばっています。
JITコンパイラはいかにRailsを速くするか / Rails Developers Meetup 2017 // Speaker Deck
ホッテントリ
はてなブログを9記事、qiitaに20記事書きました。「要約」とか「発表」と重複あるけどブクマをいただいたのは以下の記事。












OSS活動
今年リリースしたOSS
| Star | リポジトリ |
|---|---|
| ★242 | k0kubun/llrb |
| ★28 | k0kubun/yarv-mjit |
| ★16 | k0kubun/benchmark_driver |
今年はほとんどJITを作っていたのであまり新しいものを作れませんでしたね。
benchmark_driverというのはRuby Grant 2017として採択されたプロジェクトで、ツールの開発は一旦キリがつき、来年ベンチマークセットやCIの整備をやっていくところです。
あと仕事でJavaを使ってbigdam-queueというミドルウェアを作ったので、それは来年公開しようと思っています。そこでJavaに少し慣れたので、既存のRailsアプリのワーカーをJavaで書き直したりもしていました。
Contribution
今年はHamlとRubyのコミッターになったのでそのあたりに割とコミットしていました。
Ruby 3x3に先んじてHaml 5x3しました / “Hamlを3倍速くした - k0kubun's blog” https://t.co/qat70imSMT
— k0kubun (@k0kubun) 2017年2月27日
僕がRuby 2.5に入れた改善ですが、ERB 2倍高速化、String#concatの高速化、 https://t.co/YIwrymzSr7 のkeyword_initオプション追加、ERB#result_with_hash 追加、binding.irb起動時の周辺ソースコード表示、Process.timesの精度改善 などをやりました
— k0kubun (@k0kubun) 2017年12月25日
パフォーマンスをある程度改善しつつRubyのテストがJITありで全て通り、Railsアプリが普通に動くようになり、pthreadのWindows移植も終わったし、そろそろ一旦Ruby 2.6にJIT入れてみませんかという提案です https://t.co/13fXdhmxTD
— k0kubun (@k0kubun) 2017年12月26日
なんかHaml 5x3とか言ってRuby 3x3を煽っていたけど、いつのまにか自分がRuby 3x3をやっていく感じになっていました。
2018年は
ひとまず1月を目安に以下のPRがマージできるよう、残っているバグを全部取り除いていくのをがんばりたいと思います。その先で、 今ある最適化のアイデアをどんどん入れてRailsとかも速くしていけるといいですね。
ISUCON7本戦「Railsへの執着はもはや煩悩」で4位だった
ISUCON7本戦に「railsへの執着はもはや煩悩の域であり、開発者一同は瞑想したほうがいいと思います。」チーム (@cnosuke, @rkmathi, @k0kubun) で参加し、4位でした。

本戦の概要
予選より参加者は少ないと思うので軽く解説しておくと、クッキークリッカーを模したトラフィックのほとんどがWebSocketのアプリで、1万桁とかのスコアを計算する都合ほとんどのチームのボトルネックが最後までBigintの演算になるような問題でした。
僕らは15:00くらいに1位になり、その後はスコアをそれほど改善できず終わってしまいました。

方針
「@k0kubun 氏のチューニングした3倍速いRubyで優勝したらまじかっけーっす!」って話をした。 #isucon
— FUJI Goro (@__gfx__) 2017年11月25日
最近Ruby向けのJITコンパイラを開発している ので、それを使ってバーンとやろうと思ってましたが、これは開始前にgfxさんにバラされたのでやめました。
というのは嘘ですが *1 、WebSocketと聞いた時点で並列度が必要になるんじゃないかなあと思ってた *2 のと、アプリのCPU演算がボトルネックになってた *3 ので普通に使って速い言語としてGoを使うのを最初から視野にいれていました。
一方で、チーム名からもわかるように我々はRubyに最もなじみがあり計測のノウハウがあるのと、また普通にRubyのコードはGoのコードに比べ文字数が少なく見通しが良かったので、問題を把握するまでの期間Rubyで参戦し、後にGoに切り替えました。
最終形の構成概要
僕は開始2時間くらい寝起きでぽよってたので @cnosuke や @rkmathi が最初に考えた内容ですが、大体以下の感じになりました。 問題の性質上、WebSocket以外を受けるノード以外の構成はどこも同じだったと思います。
- appサーバ1 (ベンチマーク時この1台のみ指定)
- appサーバ2
- WebSocketを返すGo
- 同ホストのGo向けMySQL
- appサーバ3
- WebSocketを返すGo
- 同ホストのGo向けMySQL
- appサーバ4
- WebSocketを返すGo
- 同ホストのGo向けMySQL
やったこと
- rkmathi のブログ: ISUCON7「Railsへの執着はもはや煩悩(ry」で本戦4位だった - 明日から本気だす
- cnosuke のブログ: ISUCON7本戦で @k0kubun と @rkmathi とのチームで4位だった 「Railsはもはや煩悩(ryチーム」 - cnosuke's blog (′ʘ⌄ʘ‵)
僕は業務で一番Rubyを触っている時間が長そうで、またGoもちょっと前はよく書いてたので、主にアプリのコードをいじる担当でした。逆にインフラが絡む部分は他の人に任せています。
| 点 | やった人 | やったこと |
|---|---|---|
| 7112 | rkmathi | Python初期スコア計測 |
| 5980 | rkmathi | Rubyに変更、初期スコア |
| 4621 | rkmathi | Goも一応確認、初期スコア (その後Rubyに戻す) |
| - | cnosuke | サーバーやリポジトリのセットアップ |
| - | k0kubun | NewRelic をいれたが、99% WebSocketであるということだけがわかり、相性が微妙だったので今回は使用をやめた |
| - | k0kubun | 予選でも使用したStackProfミドルウェアを入れた。 calcStatus がボトルネックであることがわかる。 今回もRubyを使っている間結構役に立ったが、StackProf周りは別のところで解説しようと思っているので今回は説明を省略 |
| - | k0kubun | m_item テーブルを定数としてメモリに持つようにし、m_item のクエリを全てなくす。あまりスコアは変わらなかった |
| - | k0kubun | get_power, get_price のBigintの計算がボトルネックになっていたので、これをcountが0〜50の場合の結果をアプリ起動時に作るようにした。 そこそこスコアが上がった気がする |
| 8968 | cnosuke | 採番して 2,3,4 にWebSocketのリクエストを分散 |
| - | rkmathi | 2,3,4に個別のMySQL用意 |
| - | rkmathi | 再起動耐性のための設定 |
| - | k0kubun | 50個のキャッシュを500個にしてみたら全然起動しなくなった。この時点でも150までのカウントを使っていたが、150とかにしてもメモリの使用量がモリモリ増えて速攻で2GB使い切ってしまったので、Pumaのプロセスを減らすかとか考えていた(preload_app も試すべきだった)が、GILあるしなあとかまあそういうことを考えるのが面倒なので僕はここでRubyをやめることにした。 |
| - | rkmathi | innodb_buffer_pool_sizeなど、MySQLの設定とか |
| - | cnosuke | WebSocket以外を返しているノードへのWebSocketへの負荷減らし |
| - | rkmathi | サーバーで動いているのをRubyからGoに切り替え |
| - | k0kubun | Rubyにやった変更(m_item, power/priceのキャッシュ)を全てGoに移植 |
| - | k0kubun | power/price のキャッシュを 50 → 80に調整。 このパラメータをいじるだけでスコアが上がることを発見するが、起動時間が指数関数的に述びていくのでこのへんで断念したが、このあたりからcnosukeが起動時間を縮めるためこれのキャッシュをシリアライズするのを着手していた |
| - | rkmathi | 僕らが誰もGoのプロファイリング方法を知らないのでググり始める。rkmathiが速攻でpprofの使い方を理解し結果を共有してくれたのでとても助かった。始めて使ったけどtopとlistだけでかなり多くのことがわかる。あとなんかrkmathiがコールグラフをsvgにしていたが、これも便利だった |
| - | cnosuke | WebSocketだけをさばくノードでnginxをなくしてGoで直接受けるように。 今回はあまり効果はなさそうだった |
| - | k0kubun | やたら 値が1000の big.Int インスタンスを生成してるっぽかったので毎回同じものを使うように (効果なし) |
| 24227 | k0kubun | calcStatus内で 1000 * 13 のオーダーでやっているかけ算 + 比較を、13のループの外側で割り算 + ループ内比較 にすることでそこのかけ算のコストを 1/13 に。割とスコアが上がっていた |
| - | k0kubun | calcStatus内で 13回やっているかけ算を1つの割り算にできるものをもう1つ発見し、適用。 ここは1000回ループの外なのでインパクトは小さそう |
| - | k0kubun | 「1000 * 13回 のかけ算」 → 「1000回 の割り算」 に減らしたオーダーを、 「13回のかけ算」に減らした。これも効果があった記憶 |
| - | k0kubun | この時点でpprofを見る限りでは big.Int の String()が90% くらい使っていたし、GoがCPUをほぼ使い切っていたので、僕は後半ずっとこれをどうにかできないかもがいていた。なんかfloat64に変換してLog10で桁数計算したり(これは変換した時点で精度が破滅)、なんかpprofのsvgの読み方をちょっと間違えてString()の後のItoaが重いと勘違いして、Exponentialインスタンスを作る時に整数への変換をスキップしたりしたが、無意味であった。これ以降僕はスコアを上げられていない |
| - | rkmathi | puma のワーカー数いじり |
| - | rkmathi | longtext -> varchar のalter |
| - | cnosuke | power/priceのキャッシュをYAMLにシリアライズしてロードする奴を入れるが、バグのためrevert |
| 27328 | rkmathi | 再起動テストとかプロファイリングとか。我々はプロファイラを入れるとスコアが上がるジンクスを持っており、pprofを有効にした時最高スコアを更新した |
| - | cnosuke | YAMLの奴をデバッグしていて、終了間際に原因がわかるが、ベンチマークを何度も回す余裕がなさそうなので、ここで変更を加えず何度かベンチを回して終了 |
やり残したこと
気付いていたのはaddingとかが過去になった奴をまとめておけそうなくらいですが、僕らの計測の限りではそこはボトルネックではなかったので着手しませんでした。ずっとボトルネックであった big.Int.String() や、 price/power の計算結果キャッシュ数を増やすのをがんばっていたが両方失敗してこのスコアに留まった形です。
1位のMSAは、僕らはボトルネックだと思っていなかったあたりのオンメモリ化や過去の結果のマージを全て終わらせて高いスコアを出したようなので、計測は難しいですねという感じです。
我々は気付かず懇親会で知ったのは、(具体的な内容はそちらのチームのブログに任せますが) ソン・モテメン・マサヨシ チームのgoroutineを使ったものやGCのチューニングで、同じGoのアプリをいじってるにも関わらず僕らとは全く違う方向性で速くしていたようなので、その辺はGoへの慣れの差が出たような気がします。
感想
最後のISUCON本戦参加は学生枠で惨敗という感じだったのが、3年経って同じメンバーで社会人枠で健闘でき、成長した実感が得られたのがとても良かったです。
時の運次第では優勝に手が届きそうな感覚が得られたので、来年は優勝したいと思います。参加された方と運営の皆さま、お疲れ様でした & ありがとうございました!
ISUCON7予選2日目「Railsへの執着はもはや煩悩」で予選通過した
ISUCON7予選に「railsへの執着はもはや煩悩の域であり、開発者一同は瞑想したほうがいいと思います。」チーム (@cnosuke, @rkmathi, @k0kubun) で参加し、217,457点で予選通過だったようです。 正確な値は覚えてませんが、Best Scoreは25万くらいでした。

最終形の構成概要
- appサーバ1
- puma 16スレッド: 画像のアップロード/表示、雑多なリクエスト対応
- puma 2スレッド: GET /fetch だけ返す
- appサーバ2
- puma 16スレッド: 雑多なリクエスト対応 (画像はnginxがサーバ1に流す)
- puma 2スレッド: GET /fetch だけ返す
- DBサーバ
- MySQLがいるだけ
サーバ1, サーバ2をベンチマーク対象にしていました。この構成なのは GET /fetch がスコアにカウントされないため、それ以外にほとんどの時間を使えるようにするためでした。
やったこと
最終コード・他のメンバーのブログはこちら:
ISUCON7「Railsへの執着はもはや煩悩(ry」で予選通過した - 明日から本気だす
学生のころから何度も同じメンバーで出ているので、いつも通りチーム内で割と綺麗に並列に仕事ができました。
やったことと点数の推移の記録とかはやってないので、やったことだけを適当に列挙していきます*1。グラフからわかる通り多分序盤で意味のある改善が終了しており、終盤はあまりうまくいっていませんでした。
効果があった気がする奴を太字にしておく。
| やった人 | やったこと |
|---|---|
| cnosuke | 公開鍵の準備とか |
| rkmathi | リポジトリへの主要なコードの追加とか |
| k0kubun | python→ruby変更、systemdの設定のリポジトリへの追加 |
| k0kubun | NewRelicのアカウント管理、インストール。この時点では GET /fetch が支配的だったのを確認 |
| k0kubun | sleepを消したり消さなかったりした後消す |
| k0kubun | 適当にSELECTするカラムを消したり、messageテーブルにインデックスを貼ったり |
| k0kubun | rack-lineprofを眺めるがほとんど参考にならなかった |
| cnosuke | DBに入ってる画像をファイルにしてnginxから配信できるように変更 (ここで割と上位に来た)、多分Cache-Controlとかもこの辺でついてる |
| k0kubun | GET /fetch を捌くpumaのプロセス (1スレッド)をまだ何もいない2つ目のサーバーに用意し、それ以外を元々いたpuma (16スレッド) に捌かせるようにした (これも結構上がり、後々もインパクトがあった) |
| rkmathi | fetch用pumaのポートを別のサーバーからアクセスできるようにした |
| k0kubun | (本来はruby実装のclose漏れによる)fdの枯渇をOSのfdを増やしたり nginxのworker_rlimit_nofile をいじったりしてどうにかしようとあがくがうまくいかない |
| cnosuke | 2つ目のサーバーもfetchではないメインのpumaがレスポンスを返せるようにnginxを設定、画像を返すのを1つ目のサーバーに絞ったりとか |
| k0kubun | close漏れに気付いて直す、多分workloadが上がってスコアが伸びる |
| rkmathi | get_channel_list_info のループの余計な処理削り |
| k0kubun | なんかsleepを0.2とかいれてみるがスコアが下がるのでなくす |
| rkmathi | NewRelicで計測 |
| cnosuke | MySQLの設定がうまく反映されてない奴とかの対応 |
| k0kubun | GET /message のN+1つぶし、N=0で壊れるので直したり |
| k0kubun | 自分のプロフィールの時に不要なクエリを減らす、そこのSELECT *のカラムも絞る。NewRelicのブレークダウンがなんかいつもと違って全く詳細になってなくてあまりインパクトのない変更を繰り返している |
| cnosuke | MySQLがいるサーバーのメモリが使われるように設定を修正したり |
| rkmathi | GET /history/:channel_id のN+1つぶし |
| rkmathi | NewRelic見たり |
| k0kubun | さっき自分がN+1で踏んだrkmathiのコードのバグとり |
| k0kubun | GET /fetchのつぶしやすそうなN+1を1つつぶす |
| k0kubun | fetchするpumaのスレッド数を適当にいじり2つにおちつく |
| k0kubun | NewRelicのthread profilerを使うが、今回はびっくりするほど出力が見辛くはっきりいってほとんど役に立たなかった |
| rkmathi | ランダムにする必要のないsaltを固定化 |
| k0kubun | Mysql2::Clientをリクエストごとに作るのをやめ、スレッドローカルに使いまわすようにする |
| cnosuke | この辺でk0kubunがperf topを眺めてて、appサーバーがrubyよりlibzが支配的だったので、nginxのgzip_comp_levelをいじったりしている |
| k0kubun | perfを見る限りではrubyはボトルネックではなさそうだったが、ERB回り遅いのではと言われたので僕がERBを速くしたruby 2.5に変更(特にスコアに変化はない) |
| rkmathi | GET /register が静的なのでnginxだけで返すように変更 |
| cnosuke | DBサーバーにもnginxをたて、そこからプロキシだけすることでglobalな帯域を有効に使えないか試したが、うまくいかなかった |
| k0kubun | TD社内で書いた秘伝のstackprofミドルウェアを取り出し、何が遅いのか計測。rack-lineprofより今回はこっちの方が猛烈に見易かった。fetchでcounter cacheが効きそうなことに気付くが時間の都合でやらない |
| cnosuke | なんかlibzまわりの関係でgzをいろいろやってる |
| cnosuke | 画像を受けてるサーバーは1つだけだが、2つ目の方も最初からある画像は返せないか試していたが、うまくいかない |
| rkmathi | 再起動テスト |
| rkmathi | ログの出力を消したり |
| k0kubun | rkmathiの変更で/registerがoctet-streamになってて動作確認がしにくかったので text/htmlにしてる |
| cnosuke | bigintをintにしてた(のを↑のどこかでやってた)都合で壊れてるのがあって、initializeでauto incrementをリセットする変更をいれてる |
| k0kubun | 余計なcreated_at, updated_atを作らないようにした |
あとどこかでtextになってるカラムをvarcharにしたりとかしてました。
心残り
appサーバ1, 2の帯域両方をどうにかして画像のリクエスト処理に使えるようにしたかった(パスのどこかが奇数か偶数かでどちらかに固定で送るとか)ですが、いろいろ考えたけど僕はあまりいい対応が思いつかなかったです。最後 POST /message がボトルネックだったのも、MyISAMにしたりMEMORYにしたりしましたが効果はなかったですね。Redisにするみたいな大きい工事はできませんでした。
GET /fetchのレスポンスは更新があるまで止めておくのが良い(ベンチマーカーがそういう風にスコアをつけてる)、というのを感想部屋で聞いたけど、これも全く気付きませんでした。
あと、奥の手としてJITを考えてましたが全くRubyにボトルネックが移せなかったのも残念ですね。
気持ち
上位のチームには相当離されていたので、どこに自分たちが見過していたブレークスルーがあったのか知るのが楽しみです。 本戦に出られるのは学生枠で出してもらっていた時ぶりですが、いい結果を残せるようがんばります。
*1:僕以外の人のタスクは僕が把握してるレベルしか書けないので多分かなり抜けててます