Ripperによるhamlのattributeパースの話
Hamlのパーサぶっ壊れてる問題
本家のHamlは以下の入力を与えるとSyntaxErrorになる。
%div{ foo: "}" }
これはHamlが単に{と}の数だけ合わせてパースしているからである。 *1
通常この問題を解決するには字句解析器を使い、現在パースしているのが何のトークンなのか判別する必要がある。
Hamlitではこの問題を解決するため、標準ライブラリとして提供されているRipperを使っている。
そのため、Hamlitでは上記の入力を以下のように正しく解釈することができる。
<div foo='}'></div>
HamlのattributeがRubyの式としてvalidでない問題
上記のhamlの%divを取り除いた部分であればRubyのHashとして解釈できそうに見える。
しかし実際には以下のような入力もHamlのattributeとして有効である。*2
- hash = { hoge: "piyo" } %div{ hash, foo: "bar", hello: "world" } hello
もはやHashでもなんでもない。
なぜこれが動くかというと、以下のようにコンパイルされるようになっているからだ。
hash = { hoge: "piyo" }
_hamlout.push_text("<div#{_hamlout.attributes({}, nil, hash, foo: "bar", hello: "world" )}>hello</div>\n", 0, false);
つまり{}の内側は_hamlout.attributesに渡す可変長の引数の一部なのである。*3
末尾にHashっぽいのが書いてあるとそれは引数の一つとして解釈され、ここではHashが2つ渡されていることになる。
Ripperをどう使うか
パース時にどこまでがattributeか判別するため、%divを除いた以下の入力をRipperに渡すと、
[3] pry (main)> Ripper.lex('{ hash, foo: "bar", hello: "world" } hello') # [[[1, 0], :on_lbrace, "{"], # [[1, 1], :on_sp, " "], # [[1, 2], :on_ident, "hash"], # [[1, 6], :on_comma, ","], # [[1, 7], :on_sp, " "], # [[1, 8], :on_label, "foo:"], # [[1, 12], :on_sp, " "], # [[1, 13], :on_tstring_beg, "\""], # [[1, 14], :on_tstring_content, "bar"], # [[1, 17], :on_tstring_end, "\""], # [[1, 18], :on_comma, ","]]
途中で終わる…
では可変長引数ならばと先頭をメソッド呼び出しに改変して渡すと、
Ripper.lex('a( hash, foo: "bar", hello: "world" } hello') # [[[1, 0], :on_ident, "a"], # [[1, 1], :on_lparen, "("], # [[1, 2], :on_sp, " "], # [[1, 3], :on_ident, "hash"], # [[1, 7], :on_comma, ","], # [[1, 8], :on_sp, " "], # [[1, 9], :on_label, "foo:"], # [[1, 13], :on_sp, " "], # [[1, 14], :on_tstring_beg, "\""], # [[1, 15], :on_tstring_content, "bar"], # [[1, 18], :on_tstring_end, "\""], # [[1, 19], :on_comma, ","], # [[1, 20], :on_sp, " "], # [[1, 21], :on_label, "hello:"], # [[1, 27], :on_sp, " "], # [[1, 28], :on_tstring_beg, "\""], # [[1, 29], :on_tstring_content, "world"], # [[1, 34], :on_tstring_end, "\""], # [[1, 35], :on_sp, " "], # [[1, 36], :on_embexpr_end, "}"], # [[1, 37], :on_sp, " "], # [[1, 38], :on_ident, "hello"]]
とりあえず最後までスキャンしてくれる。
ここで判別に使いたい}が:on_embexpr_endになっていることに着目する。
これは本来:on_embexpr_beg(string interpolationの開始とか)と対になるトークンである。
したがって、非常にRipperの実装依存っぽい感じだが、:on_embexpr_endの数が:on_embexpr_begの数より1つ少なくなる場所でストップすればいい感じに動く。
現在のHamlitのmasterはこのように実装されている。
:on_embexpr_endの手前まではvalidな式を渡せているのでこれ以上マシな使い方は思いつかなかったが、Rubyのバージョンが上がっても動きそうな使い方をしたい…
文字列がRubyのHashとしてvalidか判別する方法
Hamlitでは、attributeの{}内の部分がRubyの式としてvalidだった場合に限り静的なコンパイルを試みて最適化をしている。
https://bugs.ruby-lang.org/issues/10405 を見ると、Ripper.sexpは引数がRubyの式としてinvalidなときはnilを返すようなことが書かれていて、Hamlitでも一度それに依存した実装を行った。
バージョンによって異なる返り値
しかしRipper.sexp(str)だけで判別するコードをpushしてみるとRuby2.1と2.0のCIが落ちた。
2.0.0-p645 (main)> Ripper.sexp('{a, b: "c"}') #=> [:program, [:string_literal, [:string_content, [:@tstring_content, "c", [1, 8]]]]] 2.1.6-p336 (main)> Ripper.sexp('{a, b: "c"}') #=> [:program, [:string_literal, [:string_content, [:@tstring_content, "c", [1, 8]]]]] 2.2.2-p95 (main)> Ripper.sexp('{a, b: "c"}') #=> nil
結局、以下のように対応した。
def valid_hash?(str) sexp = Ripper.sexp(str) return false unless sexp sexp.flatten[1] == :hash end
まとめ
Ripperは後方互換性が保証されないので必ずサポートしたいRubyのバージョン全てで動作確認を行いましょう
*1:https://github.com/haml/haml/blob/c89da381a055587fa212881f9fddd2ab3c1224ca/lib/haml/parser.rb#L625
*2:ここではattributeは内部でold attributeと呼ばれる{}で囲まれるattributeのことを指している
*3:https://github.com/haml/haml/blob/c89da381a055587fa212881f9fddd2ab3c1224ca/lib/haml/buffer.rb#L191-L199
Hamlit v1.0.0をリリースしました
3月末に、Hamlit v0.1.0を作りSlimやErubisより高速なHaml実装「Hamlit」をリリースしましたという記事を書いた。 haml-specを通しているのでHamlと高い互換性と持っていてかつ速いという宣言をしたものの、実際にリリースしてみると随所からバグ報告が上がり、
- hamlを置き換えただけでは動かない
- haml-specは互換性の保証にはならず、速いのは互換性が低いからでは?
- このベンチはHamlitがhtmlエスケープをしていないから速いだけでは?
のような声が随所から上がった。
今日、attributeのescapeに対応し、 全てのissueを潰した上で、Slimより速いベンチを出すことに成功した ので、v0.1.0での問題点やそこからの変更点などについて書きたいと思う。
v0.1.0での問題点
haml-specガバガバ問題
@k0kubun それな
— 獣耳美少女 (@eagletmt) March 30, 2015haml-specに記述されている仕様を担保するにはコーナーケースのチェックが十分でなく、完璧に実装しなくても通すのは簡単だよなあとは思っていて、リリース直後に「haml-specガバガバすぎる」という発言をした。が、HamlやFamlだとパースできない入力がパースできたり、Famlはhaml-specを通していなくてHamlitはhaml-specを通しているので、v0.1.0リリース時点では「少なくともFamlよりはHamlitのほうが互換性高いのでは?」と考えていた。
しかし、実際にリリースしてみるとhaml-specだとチェックできないケースにパフォーマンスにかなり影響のある仕様があり、それにFamlは対応していてHamlitには実装されていなかったので不当に速いベンチが出ている状態だった。 Famlの作者にパフォーマンスに影響のあるissueをいくつもいただいていたのだけれど、今日やっと直った。
htmlエスケープ
faml と slim、hamlit のパフォーマンスの差 - eagletmt's blogで、
なぜこのベンチマークで faml が遅いのか、結論から言うと、この中で faml だけ自動 html エスケープが有効になっているからだ。 haml はデフォルトでは自動 html エスケープは無効であり、hamlit もそれに倣っている。
ということが書かれていて、これは実際にその通りで、htmlエスケープはかなりパフォーマンスに影響があるにもかかわらずHamlitはベンチ上でこれをさぼっていたので、完全に不公平なベンチになっていた。前述の非互換性も含め、あまりにも不公平なので社内チャットで叩かれていた。
この仕様はhaml-specを通す都合でこうなっていたんだけど、htmlエスケープをデフォルトで無効にしたいケースは少ないと思ったので、Hamlitでもhtmlエスケープを必ず行うようにし、haml-specはHamlにescape_html: trueを渡した状態で通すように変更した。
というわけで、現在のベンチマークはHamlitもhtmlエスケープを行うようになっていて、公平なベンチに変わった。後述の工夫により、htmlエスケープが入った分Erubisに負けてしまったもののそれほどの差はなく、htmlエスケープを行わないSlimより速いベンチが出ている。
haml gemを置き換えても動かない
SlimやErubisより高速なHaml実装「Hamlit」をリリースしました - k0kubun's blogb.hatena.ne.jp
- [haml]
haml gemを置き換えただけだと動かなくて悩んでる / id:k0kubun 尻尾を捕まえたのでとりあえずissue起こしておきました
2015/03/31 12:04
このブコメをいただいたときは顔面蒼白でしたが、id:sho さんのテンプレートがハードタブでインデントされていて、Hamlit v0.1.0がタブのインデントに対応していなかったということでした。v0.3.4でタブのインデントに対応しました。 せっかくリリース直後に使っていただいたのにご迷惑をおかけしました。
v0.1.0からの変更点
attribute escape対応
faml と slim、hamlit のパフォーマンスの差 - eagletmt's blog
& や < 等が html エスケープされない
これはさすがに厳しいのでは
=演算子の結果のhtmlエスケープは実装してあったんだけど、タグの属性のhtmlエスケープに対応していなかった。これが原因でhamlit導入を断念した人もいるくらいで、相当厳しいので直した。
当然Hamlitのベンチ用コードにhtmlエスケープが入ってくるので遅くなるんだけど、brianmario/escape_utilsというC拡張のhtmlエスケープライブラリを使うことであまり速度を落とさずに済んだ。ちなみにこれはFamlの受け売りです。
消えるboolean attribute
faml と slim、hamlit のパフォーマンスの差 - eagletmt's blog
i[:url] が nil や false だったとき、<a href='false'> のような出力になる
haml では、属性の値が nil または false のときは、その属性を出力しない仕様
ちなみに slim が生成したコードを見てわかるように、slim も同じ仕様
ただ、これに関しては「hamlit ではこういう仕様です」と言うこともできると思う
これも実害があり、たとえばdisabled=''やdisabled='false'はdisabled扱いなので、普通に挙動が変わってしまう。
しかし、hrefやclassとかに関していうと、hrefにnilやfalseが入ってくる時点で何かおかしいし、classの結果がnilでclass=''がレンダリングされたからといって実害があるわけではない。
そこで、Hamlitはcheckedやdisabledのようなboolean attributeだけ消えるようにした。 このページでboolean attributeと記述されている属性は全て消える。
こうやって限定しないと、毎回href='のような文字列片を後からつなげることになり効率が悪く、遅くなってしまう。
Famlはなるべく互換性を保つ方向に仕様を倒しているけど、Hamlitはブラウザ上で挙動が変化しない範囲で互換性を削り高速化することにした。
バックトレースの行番号
テンプレートエンジンとバックトレース - eagletmt's blog という面白い記事がある。
対応していたつもりだったんだけどぶっ壊れていて、faml と slim、hamlit のパフォーマンスの差 - eagletmt's blogでもその問題について言及されている。2行直したらちゃんと動くようになった。
その他バグたち
いろいろあったけどこの記事を書いている時点で存在していたissueは全て直した。
正直最初のリリースでバグを出さないのは人間には不可能だと思っていて、多分v1.0.0にも細かいバグがたくさん眠っていると思うけど、しょうがない。人間だもの。
最終的なベンチマーク
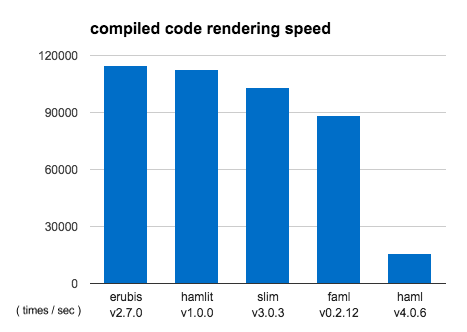
残念ながらErubisには負けてしまったものの、当初の目的である打倒Slimを達成したのでそこそこ満足度が高い。
戦争と学び
僕はFamlの作者である id:eagletmt さんにペアプロをしていただいたことがあるけど、ペアプロは自分が考える前に答えがわかってしまうことが多く、学びが少ない。 反面、自分よりすごい人のライブラリに対して対抗実装を用意して戦争をふっかけると、自分が必死で考えた成果に対してより高度な意見をいただけてかなり勉強になる。優秀な人を見つけたら、戦争をすると良い。
Slimより高速なHaml実装「Hamlit」をリリースしました
slim-template/slimのcompiled benchでオリジナルのhamlに比べ8倍高速に動作するhaml実装をリリースしました。
なぜ高速なHaml実装を作ったのか
個人的にhamlのシンタックスのほうが好きなので、「hamlは遅いからslimを使う」みたいな人を減らしたかったから。以前slimの普及に貢献したんだけど、気が変わったのでhamlを応援することにした。
実は他にも既にeagletmt/famlという高速なHaml実装が存在していたんだけどベンチを走らせたらslimより遅かったので、slimを打倒するべく再実装した。
どのくらいHamlより速いのか
自分の実装に都合のいいベンチマークを作るのは簡単なので、公平性を期すためにslim-template/slimのcompiled benchと同じものを使い、誰でも同じ環境が使えるtravisで走らせた。結果はこちら。
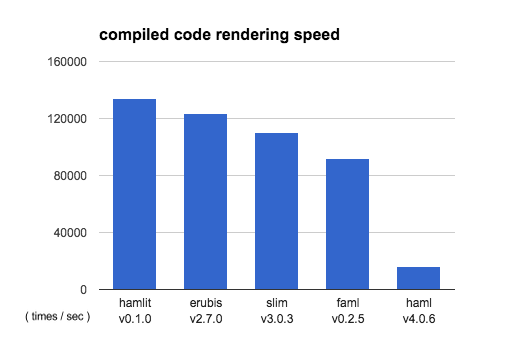
hamlit: 133922.9 i/s
erubis: 123464.1 i/s - 1.08x slower
slim: 110404.3 i/s - 1.21x slower
faml: 92009.3 i/s - 1.46x slower
haml: 15810.4 i/s - 8.47x slower
こういうhamlを1秒に1,339,22回レンダリングできるらしい。 本家の8.47倍 のベンチが出た。
ちなみにこのベンチはhamlをパースする時間を含んでいない純粋なレンダリング速度のベンチになっている。なぜこのベンチを見ているかというと、実際にRailsとかで使うときは最初にhamlがRubyにコンパイルされてActionViewにメソッドが生え、それをリクエストが来るたびに呼ぶという挙動になっているので、実際にはRubyにコンパイルする時間はあまりパフォーマンスには影響がないため。
なぜHamlより速いのか
レンダリング速度を速くするには、文字列を返すRubyのコードを最適化していくということになる。高速化のために意識したことを書く。
Templeのfilterを使う
Templeというテンプレートエンジンを実装するためのフレームワークがある。これはテンプレートをパースするクラスを作ってTempleで扱えるS式を生成すると、htmlに変換してくれるというもの。Templeはコンパイルの過程で最適化のためのフィルタを差し込むことができ、これが相当賢いのでTempleで実装してフィルタをいくつか刺すだけで結構速くなる。
さらなる高速化のためにオリジナルのフィルタのアイデアを1つ考えていたんだけど、実際にはフィルタを作ってみると速くなると思っていたベンチの結果が悪化してしまい、これ以上の最適化は難しいなという結論に達した。
ランタイムで余計なことをしない
Hamlはhtmlタグの要素が静的にコンパイル可能でもランタイムで毎回生成している。あとはタグにclassが複数あったらアルファベット順に並ぶみたいな機能があり、そういうのもラインタイムで走る。コンパイラが賢ければランタイム時の余計な処理を減らすことができるので、なるべくそうなるようにした。Templeの件とこのへんまではeagletmt/famlと大体同じだけど、内部実装は結構違くなってる。Famlはどうしてもランタイムでattributeを生成しなければならない場合はC拡張で動くのでその場合はFamlのほうが速そう。
あとはHamlは毎回ビューでHaml::Utilsをextendしてるんだけど、Railsの場合はkaminariみたいにActionView::Baseに直接includeさせちゃえばいいのでは?と思ったのでそうした。
地道に生成コードを確認して余計なコードを減らす
パフォーマンスチューニングはプロファイリングと地道な改善が重要だと思っていて、たとえば仕様上必要ない.to_s呼び出しをなくすとか、無駄な変数代入や制御構文が生成されないように工夫したりとか、なるべくstring interpolationを使うようにコンパイルするとか、何度も生成コードを見て余計な処理を削った。CIでベンチを走らせ、遅くなっていたら理由を調べて直した。そういう地道な改善の結果、slimやRails標準のerubisより速いベンチが出るようになった。
本当は考えていたオリジナルのフィルタでもっと速いコードが生成できる予定だったんだけど、rblineprofのプロファイル結果を見ながら構想していたものが実際のベンチだと遅くなってしまうという罠にハマり、あまり派手な改善はできなかった。
Hamlとの互換性は?
haml/haml-specというhaml実装の正しさをチェックするためのテストスイートがある。このテストケース全てでHamlと全く同じ文字列を生成するテストを全部通っているので、大体haml互換で動くと思う。
あと、hamlはattributeのパースが結構怪しい感じなんだけど(例えば%span{ a: '}' }はエラーになる)、字句解析に標準ライブラリのRipperを使って実装したので、文字列中に{や}が入っていてもちゃんと理解してパースしてくれる。本家よりちゃんと動く可能性がある(?)。最近書いたRailsアプリで使い始めた。
使ってみてください
ベンチで競争したものの、正直テンプレートエンジンとか何使ってもそんな全体のパフォーマンスに影響ないと思う。けどHamlはちょっと遅すぎるので、FamlなりHamlitなりを使ったほうが良いという見解です。
続き



hikarie.go #4でGoのCLIにおけるマルチプラットフォーム対応についてLTした
LTしてきた
勉強会に参加するよりひたすら家にこもってプルリ書いてるほうが好きなので去年はそういう生活をしていたけど、今年はもうちょっとアウトプットしようと年の始めに考えていた。そこで、とりあえず一発目としてhikarie.go #4というGoの勉強会でLTをした。
話したこと
GoでCLIツール書くとwindowsでも動くことを期待されることがそこそこあり、かつwindowsだけは他のOSとはだいぶ実装方法が違うので辛いという話をした。使わないしよく知らないOSの実装が重たくて思い通り開発を進められないのは厳しい。甘えていてもいられないので、僕が普段書くCLIツールでwindows対応が必要でかつそういうAPIが提供されていると作りやすそうみたいなライブラリを書いた。
go-ansiがstdout側、go-keybindがstdin側のマルチプラットフォーム対応をしてくれる。go-ansiにはもう少しAPIを足すつもりなんだけど、それがあればこの2つのライブラリを使うことで「**_windows.go」みたいなファイルを使わずにpure goのreadline代替の実装ができる。本当はそれも公開する予定だったんだけどさすがにreadline的な奴の実装をするのはそこそこ重くて間に合わなかった。
特につっこまれなかったけど、go-ansiに関しては既に似たようなのが存在しないでもない。けどまぁそれのパッケージが細分化されてて使いにくそうなのと、既存のやつが提供してる他に欲しいAPIがあったので組み直した。
ネタ作り
LT申し込む時点では何も考えてなかった上にとにかく怠惰な人間なので当日まで何もしてなかったけど、当日から徹夜を始めてすごい急いで実装して発表資料もマッハで作ってギリギリ間に合った。見に来てもらう以上はもうちょっと真面目に準備するべきだったと思う。ちゃんとしたい。
感想
久々に参加したけど和やかな雰囲気の会でよかった。
卒研発表をした
卒研終わった
2/17に卒研発表をした。
何研究してたの
モデル検査とfault injectionを行うためのモデリング言語Sandalのコンパイラの拡張を行った。
いろんな人に何研究してるのか聞かれたんだけど、そのたびに一言で説明できなくて困った。自分がモデル検査とfault injectionに関する理解がまだまだ浅いというのと、そうじゃなくても両方説明するのが難しいので、誰かに研究テーマ聞かれてもまともに説明できた試しがない。同じ学科の人に説明してもモデル検査を授業でやった人だけにしか伝わらなかった。実際にやってたことは既存の言語処理系の拡張なので、そう理解していただければと思う。
研究室所属をする際、将来知ってて役に立ちそうな分野の知見が深められるといいなあと考えていて、いくつか考えた分野の中でも最初に言語処理系のことを知っておくのがいいだろうと思ってそういう研究室を探していた。それで、たまたま同じバイトをしていたeagletmtさんとdraftcodeさんが渡部研に所属していて、あとvim confとかでdaimatzさんという渡部研OBにも会っていて、研究室の雰囲気とかが聞けた。ちょうど言語処理系を扱う研究室だったし、自分に合いそうな環境だったので渡部研にしたんだけど、実際に所属してみても良い先生や先輩たちがいて良い研究室に恵まれたと思った。
うちの研究室は所属すると最初にSchemeの処理系を作るという課題が与えられるんだけど、僕はこれをGoで実装した。 それで、夏頃研究したいテーマが思いつかなくて先生と相談したら、ちょうどdraftcodeさんが修論で言語処理系をGoで書いていたので、それの拡張をやりましょうという話になった。 研究するなら言語処理系を書きたいと思っていたし、rrrspecの検査のために設計されたというSandalのことは気になっていたので今回の研究にとりかかったという背景がある。
研究どうだったか
夏は研究の背景知識を理解するのに使っていて、秋ごろに一気に実装したんだけど、あんまり実装を進めなくても設定した目的が達成できそうだったので終了の見通しが立ち、論文も早めに第一稿を書き上げたので12月後半はかなり余裕をぶっこいて全然関係ない趣味コード書いたりしてた。
けど1月になってから、第一稿で保留してた実験が結構重いことが判明し、卒業までに実験が完了しない疑惑すら出てかなり焦った。モデル検査というのは遷移の全状態の組み合わせを検査する手法なので、検査時間は指数関数的に増大してしまうためちょっと複雑なモデルを書くと1ヶ月とかかかってしまう。研究の有用性を示す上でかなり重要な実験がそういう状況に陥ったので結構焦り、2週間くらい鬱になっていたんだけど、なんとか状態数が少なくなる別の実験を思いついたので無事研究が終わった。
今後の進路
今学部4年生なんだけど、4月には現在のバイト先にエンジニアとして就職する。
何で大学院行かないのか
僕の大学は9割弱は大学院行くし、僕と仲がいい友達の中で就職する人は見たことないんだけど、就職する。 メリットもデメリットもたくさん考えているんだけど、先に自分が進学するデメリットのほうを一言で言っておくと、「大学院に通うには非常にお金がかかるので自分が長時間働かなければならず、それだと勉強や研究にかけられる時間が少なくなってしまい、お金と時間を失って得るものが中身の無い学歴だけになるから」。
そこそこ真面目に勉強しているのもあって学費はいつも半額免除されているし奨学金も全額無利子で借りられているんだけど、地方出身の人間が東京に下宿して大学に通うのは相当金がかかるので、4年間結構バイトをした。 特に3年の後期とかは必修の1科目を覗いてそれ以外の時間フルタイムで働いていた。今の職場にはすごい待遇をよくしていただいているんだけど、それでも生活費が高すぎて収支がプラスに傾かなくて進学できるだけのお金は貯まらなかった。
僕は入学した直後からプログラマとしてバイトをしていて、2回の転職を経て今の最高の環境で働かさせてもらっている。 けど学生の本分は勉強なので、本当は今しかできない勉強や研究にたくさん時間をあてるべきだと思っていて、それにしては働く方に時間をかけすぎた。 最初の3年間は家賃光熱費込み月2万で生活できる寮に入れたのでよかったけど、4年目とかはそうじゃなくなって完全に厳しくなり、週2回のゼミしかないからよかったけど日常的に授業がある修士を続けるのは多分無理だと思った。
以上がネガティブな理由で、もしこれだけなら無限に借金してでも貴重なコンピューターサイエンスに関する知識を得にいった可能性がある。 ポジティブな理由としては、プログラマは若いうちが重要だと思っていて、研究者を育てるのに特化した機関で論文を書いているよりは企業でプログラマとしてコードを書いているほうがより自分の理想に近づきやすいと思ったから。 これが本当かどうかは誰にもわからないと思っていて、単に僕が「自分の見聞きした話からそういう仮説を立てて決断した」というだけ。
どちらかというとこういう期待があって自分の一番行きたい企業に行けるので、ほとんど不満とかなくて将来への期待のほうが大きい。 早く社会人として成果を上げられるようにがんばりたい。
RailsでN+1 countクエリを潰すactiverecord-precountを作った
追記: 2017/09/06
少しAPIが冗長なもののActiveRecordへのモンキーパッチが少ないバージョン activerecord-precounter というのを作りました。こちらの方がバグりにくいはずなので、現在はactiverecord-precounterの方を使うことが推奨されます。
概要
N+1 countクエリを最大11.7倍速くできるactiverecord-precountというgemを作った。 *1
k0kubun/activerecord-precount
N+1 countクエリ
Tweet.all.each do |tweet| p tweet.favorites.count end # SELECT `tweets`.* FROM `tweets` # SELECT COUNT(*) FROM `favorites` WHERE `favorites`.`tweet_id` = 1 # SELECT COUNT(*) FROM `favorites` WHERE `favorites`.`tweet_id` = 2 # SELECT COUNT(*) FROM `favorites` WHERE `favorites`.`tweet_id` = 3 # SELECT COUNT(*) FROM `favorites` WHERE `favorites`.`tweet_id` = 4 # SELECT COUNT(*) FROM `favorites` WHERE `favorites`.`tweet_id` = 5
私がN+1 countクエリと呼んでいるのはこういう奴で、見たことがある人は多いと思う。 これを解決するには、基本的にはcounter_cacheを使うしかない。 *2
countクエリのeager loading
しかし、スキーマを冗長化したら速くなるのは当たり前で、そんな手間をかけなくてもクエリをチューニングすればそこそこ速くなる。 で、それをActiveRecordで簡単に実現する方法がないのが問題で、そのAPIを提供するためにactiverecord-precount gemを作った。
このgemには、eager loadingのためのAPIが2つある。
precount
Tweet.all.precount(:favorites).each do |tweet| p tweet.favorites.count end # SELECT `tweets`.* FROM `tweets` # SELECT COUNT(`favorites`.`tweet_id`), `favorites`.`tweet_id` FROM `favorites` WHERE `favorites`.`tweet_id` IN (1, 2, 3, 4, 5) GROUP BY `favorites`.`tweet_id`
普通にデータを取るクエリとeager loadingのためのクエリを分けて実行するのがprecount。 クエリを分割してeager loadingを行うpreloadにちなんで命名している。
このベンチ
では、precount(:favorites)を呼ぶことで最大7.9倍速くなる。
eager_count
Tweet.all.eager_count(:favorites).each do |tweet| p tweet.favorites.count end # SELECT `tweets`.`id` AS t0_r0, `tweets`.`tweet_id` AS t0_r1, `tweets`.`user_id` AS t0_r2, `tweets`.`created_at` AS t0_r3, `tweets`.`updated_at` AS t0_r4, COUNT(`favorites`.`id`) AS t1_r0 FROM `tweets` LEFT OUTER JOIN `favorites` ON `favorites`.`tweet_id` = `tweets`.`id` GROUP BY tweets.id
JOINを使ってクエリ1つでeager loadingも行うのがeager_count。 似た挙動をするeager_loadにちなんで命名した。 なんとなくJOINしたくない気分のときにprecountの方を使うことを想定している(雑)。
このベンチ
では、eager_count(:favorites)を呼ぶことで最大11.7倍速くなっている。
counter_cacheは同じ条件で20.0倍なので、手間をかけずに11.7倍か、コストかけて20倍にするかで実装を選択すると良さそう。
使い方
Gemfileに以下を追加してbundle installするとrelation上でprecountやeager_countが使えるようになります。
gem 'activerecord-precount'
N+1 countクエリを見かけることがあったらお試しください。
ダイジェスト2014年
1〜3月
楽しい人生を送っていたのでコードを書いていなかった
4〜6月
社内のLTのネタのためにGoを始めた。Schemeの処理系とかTwitterクライアントとか書いた。
この影響で今は研究でもGoで言語処理系を書いている。
Goでテトリスを書いてDeNAでLTをした。 初期にpecoに結構コミットした。★
7〜9月
ISUCON本戦に出場した。ISUCONに参加するためインフラの勉強を始めて、多少デプロイとチューニングが得意になった。
最初Chef soloを使ってたけど最終的にitamaeに移行し、itamaeとspecinfraに少しコミットした。 ★ ★
たまにホッテントリが書けるようになった。 ★ ★ ★
10〜12月
主にActiveRecordのeager loadingの仕組みが気になってRailsのコードを読むようになり、ActiveRecord拡張を書いたりした。Railsに初コミットした。★
研究で必要になったのでGoのppのライブラリを書いてGitHubのスター100を達成した。
来年の目標
来年はもっと長い間楽しい人生を送るぞ