RJIT: RubyでRubyのJITコンパイラを書いた
僕はRustでRubyのJITを書く仕事をしているのだが、去年の12月くらいから、趣味ではRubyでRubyのJITを書いている。 それまではC言語でコード生成を行なうMJITを5年くらいメンテしていたのだが、先月、Rubyで機械語を直接アセンブルするRJITに差し替えた。
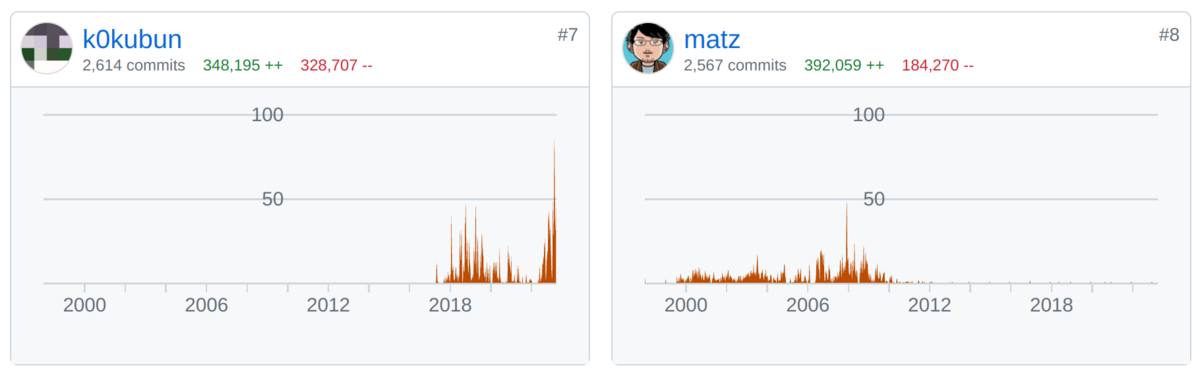
なので、今Rubyのmasterブランチには、会社で業務として開発しているRust製のYJITと、僕が趣味で開発しているRuby製のRJITの2つのJITコンパイラが存在している。余談だが、JITの開発をしすぎてRubyの作者であるまつもとさんのコミット数を最近抜いた。
なぜMJITをやめたのか
MJITも結構がんばっていて、去年開発していたRuby 3.2ではMJITのコンパイラの実装をCからRubyにフルスクラッチした上、バックグラウンド処理をpthreadからfork + SIGCHLDで行なうように変えたり、早い段階からコンパイルを可能な限りまとめてバッチ処理してwarmupを高速化するなど、結構手を加えていた。
しかし、MJITの改善について考えれば考えるほど、生成コードがC言語に縛られているせいでコードの動的書き換えを前提とした最適化が難しいことが気になってしまった。そこで、12/10にMJITのコンパイルのバッチ化をマージした次の日から、その問題を抱えていない設計を持つRJITに着手し始め、3ヶ月ほどかけて公開に至った。
RJITでやりたいこと
MJITのコンパイラがRubyになったことで、Ruby 3.2からモンキーパッチを使ったJITコンパイラの差し替えが可能になった。これを使ってJITを開発している人が2人いて、このバックドアを残すことがRJITの主目的の一つである。僕もその2人もYJITの開発に参加している*1ので、オリジナルのJIT開発の経験をYJITにフィードバックするのが最終的な狙い。YJITを越えるのは特にゴールではないため、本番環境では引き続きYJITを使うことが推奨される。
YJITの開発ではコンパイル速度やメモリ消費量に細心の注意が払われており、ベンチマークの改善に即座に貢献しない複雑な実装はマージしないで塩漬けにする傾向にある。僕は既にYJITのシンプルなメソッドインライン化やSplittingなどのPRを用意したが、これら単体では大きな速度改善に繋らなかったため、マージされなかった。RJITはそういった試験的な実装を継続的に試せる環境にしたいと思っている。実際に成果に繋ったものはYJITにポートするようにしていて、最近もそのようなPRをマージした。
RJITのアーキテクチャ
MJITはメソッドJITだったが、RJITではYJITの実験場という目的から、YJITと同じくLazy Basic Block Versioningというデザインで作られている。それだけでなく、僕自身がYJITの仕組みを学びたいという目的もあり、codegenもほぼYJITの実装をなぞって作ってあるため、Yet Another YJITみたいな状態になっている。
一方で、アセンブラに関しては誰の実装も見ずに完全に自力で書き上げた。これは何というか、これまでC言語に依存してコード生成をしていたので "本物の" JITコンパイラを書いているという感覚がなかったので、Intel SDMを読み込んでここをちゃんと書いたことでそのコンプレックスが今回解消された。
アセンブラのAPIはなるべく生成コードに近くなるようにしてあって、例えば以下のアセンブリにあたるコードは、
lea rax, [rbx + 8] mov rdi, 0
asm.lea(:rax, [:rbx, 8]) asm.mov(:rdi, 0)
それから、Ruby 3.2でMJITをRubyに書き換えるにあたり、CのstructにRubyからシームレスにアクセスする仕組みを結構時間をかけて作ったのだが、これはRJITにそのまま引き継いできて便利に使っている。RustのbindgenではCとの連携機能が非常に限られており、例えばstatic inlineの関数は呼び出せないのでYJIT用に手動でラップしないといけなかったり、Cのstructのfield一つごとにそれにアクセスするための関数をYJIT用に用意して使うみたいな感じなのだが、RJITではそもそもそこを自前で作り全自動化することで快適な開発ライフを送っている。
例えば、YJITだとこのようなコードがあるが、
let stack_max = unsafe { rb_get_iseq_body_stack_max(iseq) };
RJITだとこうなる。
stack_max = iseq.body.stack_max
RJITのパフォーマンス
1日1回Rubyのベンチマークを走らせて表示する rubybench.github.io というサイトをメンテしていて、 このサイトでの最新の結果は以下のようになっている。

MJITの性能はRJITをマージした時のPRを見て欲しいが、MJITはこれらのベンチマークでは多くの場合インタプリタより遅いという状態だったので、RJITでは (ruby-lsp以外は) これだけ高速化できているというのは大分進歩した感じがする。MJITのrailsbenchでの性能は、かなりがんばってチューニングして5%速くなるみたいな感じだったが、RJITでは安定して30%くらい高速化している。
セルフホストJIT構想
RJITでRJITをJITすると再起呼び出しになったり、ありとあらゆる理由で壊れるので現在はRJITそのものはインタプリタ実行になっている。 インタプリタの性能でRust実装のwarmup速度に追いつくのは無理な話だが、RJITのコンパイラが十分に発展したら、 別プロセスでも再利用できるようなコードを生成するモードを用意して、RJIT自体をRJITでプリコンパイルして添付する、 みたいなことを妄想したりしていた。
それはそれで面白い取り組みになると思うが、RJITがrailsbenchで生成するコードがYJITとほぼ同等になった今railsbenchでの性能を比べてみると、warmup速度以前にピークタイムもYJITにそこそこ差が開いているという気付きがあった。何か実装漏れがあるとかならわかるが、僕の知る限りrailsbenchに影響しそうなところは全てポートしてきたという理解なので、やや不思議な状態になっている。そこで GC.disable をしてみたところ、性能差がかなり縮まった。そのため、RJITが生成するオブジェクトがGCに与えるオーバーヘッドがまあまあ大きいということになるが、これにアプローチする方法は今のところ思いついていない。
まとめ
僕はRubyのJITを書ける仲間を増やしたいという思いがあり、RubyKaigi 2023ではそういう人を増やすためのトークをする予定。松本で僕と握手!