セルフホストで学ぶJVM入門
RubyのJIT開発でやろうと思ってることが大体 @_ko1 さんの作業待ちでブロックしていて暇なので何かを書こうと思い、JVMを書くことにした。 まだその辺のアプリを気軽に動かせるレベルでは全然ないが、別に秘密裏に開発する必要もないと思ったので公開した。
これの紹介と、現時点で学べたことをこの記事に記録しておく。
何故JVMなのか
仕事でJVM言語を使っている
僕が所属しているTreasure Dataでは、大雑把に言うと本番サーバーのサービスは大体Ruby, Java, Scala, Kotlinで書かれている*1ので、既にRubyのVMはある程度わかる*2ことを考えると、JVMさえ理解してしまえば社内の主要な言語評価系を抑えたことになり、運用面で活躍の機会が増える気がしている。
また、自分が最近一番書いているのはKotlinなのだが、JVMで動かしていることに由来した問題が垣間見えることがあるので、JVMに詳しいとその背景を理解したり問題に対処したりするのに役に立つと思っている。
OpenJDKの良いところを今後CRubyで真似したい
Ruby 2.6で導入されたJust-In-Timeコンパイラの開発をしているので、なんか遅くて困った、という時に他の処理系が同様の問題をどう解決しているか参考にしたいことがある。
その上で、Rubyと同じくスタックマシンであるHotSpot VMは、既に長く運用され洗練されたJITを持っているのですごく参考になりそうだし、CRubyと性能を競うJRubyやTruffleRubyもJVMで動くので、JVMの挙動が解析できると他のRuby処理系の挙動理解にも役に立つ感じがする。
何故Javaで実装したのか
昔C言語のコンパイラをCで書いてセルフホストしようとして結局途中でやめた、ということがあり、今回こそセルフホストにこぎつけようと思いJVM言語で書くことにした。
JVM言語の中でもJavaなのは、仕事で使うのでJavaのコードを割と読む機会があるが、書いてるのは大体Kotlinなので、Javaを書く方の経験の足しにしておこうと思ったため。*3
JJVMは今どこまで実装してあるか
testディレクトリに置いてある奴は動くが、VM命令と一対一対応みたいなものしか置いてないのであまり参考にならなそう。テストを書くのが面倒くさいので、セルフホストを主な結合テストとして利用しようとしている。
それから、Systemクラスの初期化に10秒くらいかかるので起動がめちゃくちゃ遅いというのと、割と自明に実装できるところもテストを用意していないうちはRuntimeExceptionで落としてわざと動かさないでいる場所が結構ある (nop命令すらコメントアウトしている) ので、読んでいる皆さんが過去に書いたアプリケーションを動かしてみる、とかはおすすめできない状態にある。
BytecodeInterpreter.javaを眺めたり、-Xjjvmtraceというオプションの出力を眺めると簡単に雰囲気がわかると思う。
実装スコープ
以下のものを実装している:
Javaを使うと本来クラスファイルパーサーはimportするだけでも使えるが、Javaバイトコードそのものに多少興味があったので自前で書いている。クラスファイルパーサーを書く時の雰囲気は他に最近JVMを趣味で書いてる人たちが 書い てた ので省略する。
どこでインチキをしているか
クラスファイルパーサーでは異常な真面目さを発揮しているが、それ以外の場所は手抜き感に溢れている。
GCがある言語でインタプリタを実装すると、一般に、GCはホスト言語のものをそのまま使えることになる。最近JITばかり書いていたのでJITはお休み。
上述した "ホストJVMのbootclasspathの利用" により、ホストのランタイムライブラリに依存している*4。
また、とりあえず達成感を得るためにセルフホストまで行きたいが、何か面倒っぽい細かいところの呼び出しをスタブして逃げたりしている。が、 System.out の初期化とか PrintStream.print() の実装は可能な限り下のレイヤーまで本来の挙動を再現するよう実装してあって、Hello Worldにも結構な労力をかけている。
一番インチキっぽいのはpublicなネイティブメソッドをJavaで実装するパートで、例えば System.arraycopy の実装はJavaで System.arraycopy を呼ぶだけなのである。セルフホストする都合Javaで書かなければならないことを考えると保守性も性能も共に最高の実装のはずだが、勉強にはならない。どうか NativeMethod.java ファイルは探さないでほしい。
セルフホストの進捗
java コマンド相当のCLIで -help が動くようになった。…以上である。
System.out.println() を完全にスタブした状態で -help でのセルフ起動・終了が達成できた時も結構な達成感があったものの、それ以降はセルフホストらしい進捗はまだない。というか、肝心のインタプリタ部分の実行に至っていないので普通はセルフホストとは呼ばない状態にあると思う。
その次のマイルストーンとして、上述した通り System.out.println() をなるべくスタブを避けて実装する、というのをがんばった*5。これでも結構動いててがんばっている感じがするが、次はやはり評価系をセルフホストできる状態にしたい。
これまでの開発でJVMについて学べたこと
(このセクションは、Javaのモヒカンの方々は多分皆知ってる内容なので読み飛ばして欲しい)
Java バイトコードの読み方
公式ドキュメントのThe class File FormatとThe Java Virtual Machine Instruction Setを読めばわかる話なので、印象に残ったことだけ触れておく。
クラスファイルパーサーを書くと、descriptorと呼ばれる ([Ljava/lang/String;)V みたいな初見では奇妙なフォーマットが自然に理解できるようになる。これはクラスファイルに対し javap -s すると出てくるが、普通に生活してても、Kotlinを書いてる時に same JVM signature というエラーとかでdescriptorにお目にかかることはある。
あと、深淵な理由により.javaが得られず.classだけが渡された時に、 javap -v で挙動を解析したりバイナリエディタで勝手にハックしたりできて便利そうな感じがする。まあIDEAのJava Decompilerとかあれば、無理してjavapの出力を読まなくてもいいこともあるかもしれないけど。
Kotlinコンパイラが生成するクラスファイルも読んで違いを見てみたいと思っているが、それは未着手。
標準のクラスのソースやjarの場所
OpenJDKの公式リポジトリはMercurialらしいが、僕はGitしか使い方がわからない*6ので、 https://github.com/openjdk/jdk のミラーをcloneして使っている。仕事では openjdk-8-jre 上でKotlinを動かしていることもあり、少し古いがJDK 8系のタグ(jdk8-b120 とか)をチェックアウトして読んでいる。
主要なクラスは大体 jdk/src/share/classes に入っているのでそこを探すと様々なクラスの実装が読める。まあ openjdk/jdk にある全ファイルをまるごと unite.vim でフィルタして探してるので僕は jdk/src/share/classes とかは記憶してないけど。
また、JDKを動かしている時などに使われる実際のクラスファイルは、JDK 8系だとJDKのディレクトリ内の jre/lib/rt.jar を jar -xvf で展開すると出現する。Java 8を使っているのでJJVMの実装は System.getProperty("sun.boot.class.path") してこれを探しにいっているが、より新しいバージョンではこれらは違うパス / プロパティ名になっているらしい。
クラスやフィールドがどのように初期化されるか
The Structure of the Java Virtual Machineを読むと、JVMの型にはPrimitive TypeとReference Typeがあり、前者のデフォルト値は0、後者はnullになることが書かれている。
クラスのstaticなfieldの初期値は、何も指定されていない場合は最初から上記のルールの通りの値になる。そうでない場合、内部的には、初期化するクラスの <clinit> *7 を呼び出して putstatic 命令で初期化されている。初期値が定数な場合はクラスファイルのfield部分にConstantValueというattributeがついていてそこにconstant poolへのindexがあり静的に初期値が解析できるが、動的な初期値だと <clinit> のCode以外ではクラスファイルレベルを見ても初期値がわからないように見える。
OpenJDKには Threads::create_vm という名前からしてVMの初期化に使いそうな関数があり、いくつかのクラスはそこで既に initialize_class されるが、Systemクラスに関しては更に call_initializeSystemClass から System.initializeSystemClass() というメソッドが呼ばれていて、皆さんがよく使う System.out 等はそこで初期化されている。
オブジェクトの生成はバイトコードでは new 命令の後 invokespecial 命令で <init> (コンストラクタの内部的な名前) というメソッドを呼び出して行なわれるが、new 命令のドキュメントには上記の通りのデフォルト値にインスタンス変数を初期化することが明示されているので、コンストラクタに入った時点でPrimitive Typeのインスタンス変数は0になっていることが信頼できる、といったことがわかる。
JVMがRuby VMと違うところ
Rubyだとパーサやコンパイラみたいなフロントエンドが評価系と同居している、みたいな当たり前の話は省略する。
バイトコード省サイズ化の努力が見られる
.jarや.classで配布することを見越してか、単にJVMの内部実装の都合に合わせたのかはわからないが、クラスファイル内で出現するあらゆる名前はcontant poolで必ず共有されている。*8
VM命令やオペランドが1ワード使うRubyとは異なり、Javaバイトコードでは名前の通り命令のopcodeやオペランドの基本サイズは1バイトになっている。オペランドがconstant poolの参照の時はインデックスの指定に必要なバイト数に応じて別のopcodeが使われていたり(ldc, ldc_w)、頻出オペランドがopcodeにエンコードされてたりする(iconst_0, iconst_1, ...)。
頻出オペランドで命令が特殊化されるのはRubyにもあるが、それは命令の実装におけるオペランドのインライン化(による最適化)が目的なので、それも兼ねているかもしれない。
Primitive Typeごとに命令が細分化され、ネイティブメソッドも少ない
Ruby VMだとPrimitiveっぽいクラスの処理のほとんどはネイティブなメソッドかその最適化用のVM命令でCで記述されているが、静的に型が定まらないことがほとんどなRubyの特性上、その最適化命令の実装はあるクラスに特化したものにしておく、ということが難しい。
なので Integer#+ 用の命令があるわけではなく、その最適化命令はどんな #+ でも動く作りになっていて、例えば Array#+ の呼び出しは Integer, Float, String など他の様々な型のチェックの後 Array かどうかがチェックされやっと動く、という作りになっている。
JVMの命令でその命令に相当するのは iadd, ladd, fadd, dadd で、ちゃんとPrimitive Typeごとにバラバラになっている。配列の操作はそれぞれまた別の命令があるし、 String というのは所詮 char[] value というfieldを持つ普通のオブジェクトに過ぎないので、 iadd および配列操作の命令まで落とすことができる。
今ではどちらもJITを持つ処理系だが、JITをする上でどちらが最適化に都合がいいかというと、圧倒的にJVMの状態の方が良い。そもそも1つの命令が様々なクラスに対応してて分岐が多かったりすると、命令単位で色々こねくりまわしてミクロな最適化をするのが難しくなる。ネイティブなメソッドは、インライン化してVM命令と混ぜて最適化する、ということが難しい *9 ので、全てがVM命令の組合せで定義され数値演算や配列操作の小さな命令たちに落ちるのが理想である。
ところでRubyでも Integer#+ 専用の命令を使うようにすることはできないことはなくて、「Integer が来たら Integer#+、それ以外なら命令を別のに書き換えつつフォールバック」というような命令を含む全命令セットのリプレース提案をした人がいた。これで命令内の型分岐は1つに絞れるが、全命令リプレースはリスクが高いので現状のVMにその特化命令アイデアだけ入れるパッチを書いてみたことがあるが、ベンチマークでの結果があまりよくならずまだ入れていない。
所感
手を動かす時間が長すぎてOpenJDKの実装を読む時間がそれほど取れてないんだけど、これで割と読む準備ができてきた気がするので、気になっていたところを読むのをそろそろ進めていきたい。
*1:コンソールとかは例えばJavaScriptで書かれているし、TDで使われている言語がこれだけという主張ではない。若干本番から離れたところではPythonが使われているが、まあ雑に捉えると大体Rubyと同じと思って生活している。
*2:単にRubyと書く時はCRubyのことを意図している。JRubyを使っている箇所もあったが、社内のJRubyコミッターの人数よりCRubyコミッターの人数の方が多いので…というのは冗談だけど今は大体CRubyで動いている。
*3:同様の目的でJavaだけでAtCoder水色にしたり、趣味でも現職でもJavaで一からサービスを書いたりしてはいるが、長くメンテしているものが少ない
*4:もちろんJJVMの方で評価しているのでこれはそこまでインチキではないが、例えばAOTコンパイルで動かそうとすると壊れるリスクがある
*5:というかそれをがんばったせいで、1秒もかかっていなかった初期化が10秒になってしまった。
*6:念のため補足すると、Rubyの公式リポジトリのSubversion→Git移行に僕が結構貢献していた、という前回の記事にかけたジョーク
*7:javap -v だと static {} になってしまうのがやや不満。<init> も同様
*8:RubyのInstruction Sequenceをシリアライズした時のフォーマットがどうなってるか知らないというか、Rubyではそれはそれほど重要ではなくあまり興味もないので、この部分に関して公平な比較は特に書いてなくて申し訳ない、が言及したかった
*9:GraalのSulongではそういうことをやれると記憶してるけど、同じことを一人で実装・メンテしたいかというと、やりたくない…
令和時代のRubyコア開発
Ruby Core Development 2019というタイトルでRubyKaigiのCFPにプロポーザルを書いたのだが、 もう一つ書いた方の話が採択されたのでその話はしなかった。
さて、今日はRubyコア*1の開発がSubversionからGitに移った節目でもあったので、そっちのトークで言いたかったことの一部を記事にしておこうと思う。
Subversion → Git 移行 [Misc #14632]
去年くらいから @hsbt さんが cgit というGitフロントエンドを使ってGitリポジトリの準備を始め Misc #14632、ついに今日正式にcgitの方がupstreamになった。平成の時代でSubversionでのtrunkのRubyコア開発は幕を閉じた。
この辺を進めているのは主に @hsbt さんな中、僕がこれを偉そうに書いたり今回のRubyKaigiで壇上でアナウンスをやったりしていたのは、必要な作業量が多そうで半年くらい前から僕も移行作業を手伝っていて、割と多くのパートで貢献していたため。
そもそも何故Gitにするのか
他の場所でのSubversionの用途は知らないが、Rubyコミッタの間では、大体以下の話が散見された。
- 最近は多くのコミッタがgit-svnを使っているが、git-svnを使うのが微妙に面倒くさい
- Subversionだとコミッタ以外のパッチをマージする時にauthor情報がコミットメッセージにしか残らない
- git blame や https://github.com/ruby/ruby/graphs/contributors に名前を残したい層がいて、その人たちのcontribution意欲を削いでいる
GitよりSubversionの方が優れている点も当然あるが、Git化したいという話は作者のまつもとさんが時おり言っており、 MatzがGoと言えばGoなのである。
何故GitHubではなくcgitなのか
- 極めて重要なメンテナであるEric Wong*2がプロプライエタリソフトウェア(GitHub)を使わない主義である
- 彼はWindowsには絶対に触らないし、ブラウザもCUIなのでJavaScriptがないと動かないCIは見ない
コミットhookが svn.ruby-lang.org のサーバー上で動くことを多少前提にしているのでいきなりGitHubに持っていくと少し大変という話もあるが、ブロッカーなのは以上の一点しかないという理解をしている。
今のところ彼はメンテナをやめる意向をたまにRedmineに書いているがおそらくまだ公式にそうなったという感じではない。僕らがGitHubでマージボタンを押せず、自分たちでgitサーバーを運用するコストに見合うくらい彼の貢献や活動力は貴重なので、すぐにGitHubに移行しよう、とはならない気がする。特に、auto-fiberと呼ばれている目玉機能は彼が作ったがまだコミットされていないのである。
Git化に必要だった作業達
- コミットフック https://github.com/ruby/ruby-commit-hook のGit対応 (いっぱい機能がある)
- Rubyリポジトリ内の
tool/*スクリプトのGit対応 - 公式のissue trackerであるRedmineのGitリポジトリ対応
- RubyCI や ci.rvm.jp など、Subversionを元に動いていたCIやbotのGit移行
- cgitの用意、運用、アナウンス
最初の2つを僕がやった。半年前にガッと進めて、かつ今回のRubyKaigi中もガッとやってやっと終わった程度には、作業量があった。
懸念した点
- リビジョンがインクリメンタルな数字ではなくなる
- chat botのbisectとかCIがこれに依存していたりするので移行が必要になる。が、git bisect通りの挙動をすればまあいいはず
RUBY_REVISIONの型がIntegerがStringに変わってしまう。これはどうしようもない。すみません。
- 我々のcgitの運用方法が共有ユーザーでsshしてコミット、なので署名しない限りあるコミットを誰がコミットしたのか信頼できない
- GitHubのマージボタンをどうにか使えるように双方向同期するか?
- GitHubへの移行を諦めるならいつかやりたい気はする。実装が面倒そうなのでいつか。
- trunk を master に変えるか?
- Gitでtrunkブランチを使うのは不自然で間違えるのでやめたい。が、CIとかが決めうちしてそうなので、一度に壊しまくらないようそれの移行はタイミングを分ける
- @yugui さんが
git symbolic-ref refs/remotes/origin/master refs/remotes/origin/trunkというのを共有していた
- 古いバージョンのブランチをGit化するとそれ自体が非互換になりそう
- なので 2.6 までのブランチはSubversionのままやることになった
- Subversion用のViewVCでクローラーがサーバーに負荷をかけており、同居しているcgitがたまに使えなくなる
Git化してよかったこと
- git-svnを使わずにgitで普通〜に開発できる。
- コミットすると https://github.com/ruby/ruby/graphs/contributors に名前が残るのでcontributorのモチベーションが上がる?
- 僕はコミッターになる前の機能のgit blameが自分じゃないのはちょっと寂しいなと思っていた
- まあでも実際そこに名前が残らないから何もしない、という人はどの道コミットしないような気もする :p
- 将来GitHub化するなりGitHubからも同期するなりでPull Requestのマージボタンが押せる世界が近付いた
- 今は多くのコミッター(僕も含む)はPull Requestなしでいきなりtrunkに突っ込んで何かあったらrevertするという原始的な開発手法を採用しているが、trunkのCIが破滅しがちで辛いので、文化を変えた方がよさそう
C99化 [Misc #15347]
古いVisual StudioやSolarisで動かないことに懸念があり、Rubyコアは去年まで長らくの間C89/C90で開発されていた。
どういうことかというと、 // コメントが書けないとか、boolが使えないとか、関数途中で変数を宣言できないとか、arrayやstructの便利な初期化シンタックスが使えないとか、そういう感じになる。
2019年にこれはしんどい。C99というのは1999年だからC99なんだけど、もう20年たったのだ。もう平成は終わりなのだ。
記事が長くなってきて疲れたので適当にまとめるが、Ruby 2.7からplatformの要求バージョンを上げるなどで対応した。また、C99を全てはサポートしていないplatformがあるが、それら用に重点的にCIを回すことで対策をするなどした。詳細に興味がある人は https://github.com/ruby/ruby/pull/2064 をどうぞ。このプロジェクトは主に僕が主導していた。
インデントのハードタブ廃止 [Bug #14246]
去年の途中まで、Rubyコアはインデントが4つまではスペース、8つに達するとハードタブ、その次の4つはスペース、といった方法でインデントされていた。 僕のエディタ(Vim)で普通にRubyコアのリポジトリを開くとデフォルトではインデントがめちゃくちゃになりがちで、vim-cruby をいれ、cloneする度に .vimrc.local を書きそれを有効にする、といった苦労があった。また、GCCやClangがVMのコードをpreprocessしてJIT用のヘッダを生成する時にタブだけ1スペに変換されるという挙動があり、gdbでデバッグするのがものすごく辛い、という実害があった。
Rubyの二大コミッタのうち、 @nobu さんが上記の方法でコミットし、 @akr さんが常にスペースだけでコードを書いていてインデント方法陣取り合戦みたいになっていて、@shyouhei さんがどっちかにしてくれという話をしたのが Bug #14246。結果全部スペースに倒すことになった。
今はいじった行や新しい行にハードタブが含まれているとbotが勝手にspaceに変換してくるというフックが入っており、revertする時とかに鬱陶しいという話があるが、一気に置換すると、git blameの歴史が一層積まれる他にbackportのconflictが辛そう、という話があり妥協でそのままになっている。まあ、なんか困ったらファイルごとに一括置換していくなりしたらいいと思う。
僕は他に misc/ruby-style.el の更新とかをやったりした。
MinGW, JIT 向けCIの追加
RubyのJITは最初のWindows platformとしてMinGWに対応したため、MinGWのCIが欲しくなった。 AppVeyorでMinGWが動かせるので、AppVeyorにこれを追加した。これは確か僕が最初にやって @nobu さんが修正した感じだった気がする。
また、JITは普通は非同期にコンパイルを行なうが、JITがリクエストされた瞬間同期的に必ずメソッドをコンパイルするようにすると、結構シビアなJITのテストができる。なので、これをWerckerといういままで使ってなかったCIで実行することによって、JITはテストされている。これのおかげでJIT向けにがんばってテストを書かなくても、既存のテスト資産全てがJITの開発に利用できている。すごい楽!!! これは僕用なので一人でメンテしている。
Werckerはコミットごとに1回なんだけど、ランダムで発生する失敗を見つけまくるため、 @ko1 さんが http://ci.rvm.jp/ というCIをメンテしていて、そこでJITのCIが24時間ぶん回っていて、これが2.6のバグ減らしにかなり貢献していたりする。
bundler, bundled-gems 向けCIの追加
@hsbt さんがAzure Pipelineに新たなCIを設定した。僕もちょっと手伝った。 これは標準ライブラリであるがRubyコアに直接存在していないbundled-gemsや、 存在はするが時間がかかるのでCIに参加させにくいbundlerのCIを、並列度が高く新設のAzure Pipelinesで実行しようというもの。
Azure Pipelinesが新しすぎて通知周りがいろいろいけてないとか、単純にbundled-gemsのCIが不安定などでtrunk限定で実行している。 Ruby trunkでbundlerやbundled-gemsが動かなかった時にすぐ気付けて大変便利。 最近 @nobu さんがおもむろに加えた変更でbundlerのテストがコケたので僕がbundlerにパッチを送って直した、ということがあった。
まとめ
Rubyの開発はとても快適になったので今すぐ https://github.com/ruby/ruby にPull Requestしよう!!! *3
2018年にやったこと
ハイライト
- 所属しているTreasure DataがArmに買収され、給料が増えた
- ジョブタイトルがSenior Software Engineerになった
- Ruby 2.6のJITコンパイラを開発し、Ruby Prize 2018をいただいた
ARMに入社しました / “The Next Chapter - Treasure Data” https://t.co/f5FdgHM4wI
— k0kubun (@k0kubun) August 2, 2018
「Ruby Prize 2018」受賞者は国分崇志様です!おめでとうございます! #rubyworld pic.twitter.com/H6VYIRgPjV
— RubyWorld Conference (@RubyWorldConf) November 1, 2018
おかげ様で経済的に大分余裕ができ、結婚式や新婚旅行、奨学金繰り上げ返済などを経たものの、前年比で結構資産が増えた。
200万ほど繰上返還して奨学金完済した
— k0kubun (@k0kubun) May 28, 2018
発表
JITの話を4回、JITに関係ない発表を2回やり、あとRuby Prize受賞スピーチがあり計7回登壇した。そのうち海外での登壇は2回。
RubyConf, RubyKaigi, RubyElixirConf Taiwan, TD Tech Talk: JITの話
2年くらいずっとこれに取り組んでいるのもあり、過去にJITの話を7回やってて、来年も既に2つJITで話す予定が入っている。自分自身が飽きないよう、可能な限り毎回スライドを新作にしたり、過去に話してないネタを話すようにしているが、そろそろ聞く側が飽きてる気がするので別のネタを考えたい…。しかし「JITでRailsをX倍速くしたぞ!!」と言える日が来たら、是非一度壇上でやりたいと思っている。
年の始めにオンライン英会話をやった後、会社で英語話者ばかりのチームに入ったのもあり、5月にRubyElixirConfで話した時より11月にRubyConfで話した時の方が英語が改善したと思えたのはよかった。2年前に初めてRubyConfで話した時はほとんど資料読んでるだけだったし、成長した感じがする。
Ruby Association Grant: Rubyのベンチマーク環境の話
あまり知られていないと思うけど、今年Rubyのベンチマーク環境は一新された。具体的にはruby/rubyリポジトリのbenchmarkディレクトリは去年から今年にかけて私が開発した benchmark_driver.gem というベンチマークツールで実行されるものに移行され、既存のRubyBenchといったシステムもこれをベースに動くようになった。
何が嬉しいのかは資料に書いてある通りだけど、そもそもベンチマーク環境の整備というのは言語処理系の最適化を考えるのに比べると(私にとっては)あまり面白みがないのでお金でも貰わないとやらないと思うんだけど、その割にはとても重要な話で、Rubyアソシエーション様や協賛企業様のおかげで今回私が50万円をいただいてこれを完遂できたのはとても良かったと思う。
Rails Developers Meetup 2018: マイクロサービス化の話
2017年11月〜2018年2月くらいにかけてやっていた仕事の話。コントローラと密結合しているモデルの実装がRailsアプリとは別のリポジトリでYAMLとして管理されていて、かつそのYAMLのメンテをするチームが異なることから、そのYAMLだけAPIで動的にリリースされているという状況があった。
あるモデルに変更を加える場合、それに対応するコントローラの実装も同時に変えてリリースすれば少なくとも同じプロセス内では整合性が取れて壊れにくいのだけど、それらが独立してリリースされている上、そのYAMLに後方非互換な変更が加えられることが多く、その全てが障害に繋がっていた。「モデルだけ切り離すんじゃなくて、APIの実装として独立させた方が疎結合になって安全なんじゃない?」という発想で生まれたプロジェクト。
サービスが分散するとそれはそれでまた新たな問題を解決しないといけなくなるのだけど、上記の問題は解決したし、去年の状態に比べるとかなりマシな状態になっていると思っている。
仕事
2017年は主にRailsアプリケーションの開発をしていたが、2018年はSREチームに移りレガシーなインフラの改善を進めていた。具体的には、以下のようなことをやっていた:
- 障害のあったインスタンスの自動ローテーション、負荷の高いサービスのAutoScaling有効化
- スケールアウト時のインスタンスの起動時間短縮や安定化のためのパッケージング、Docker化
- 乱立していたデプロイ基盤の統一化
- 開発やテスト、本番用のクラスタをオンデマンドに作れるマルチクラウドな基盤の整備
僕がチームに入る前Rubyを書ける人よりPythonを書ける人の方が多かったのと、当時RubyがLambdaでサポートされていなかったのもあり、AWS Lambdaに乗せるPythonのコードを書く仕事が多かった。
弊社はSREチームも割と最近まで存在せず、創業時ごろに整備されたインフラを少数の人が片手間でメンテしつつほとんどの人はプロダクトの開発に集中してるという雰囲気だった。これはある程度の期間うまくいくけれど、組織やビジネスが大きくなると少しの負債が大きな障害や開発速度の鈍化に繋がるので、このくらいの規模・タイミングで基盤の改善に投資するのはビジネス上も効果が高いだろう、と思いながら仕事をしていた。
僕は長期的にはSREというよりSWE(ソフトウェアエンジニア)でやっていくつもりなのだけど、社内でもかなりトラフィックが多めなサービス達の負債を返済するべく足を突っ込んできた結果、色々ご迷惑もおかけしてしまったが、オペレーション上色々経験させていただけたのは良かったと思う。
なお2019年の頭からバックエンドチームに移ることになっていて、主にJavaでミドルウェアや分散システムを書く感じになると期待している。最近入った人たちの間ではKotlinが流行っている様子。
執筆
初めて執筆っぽい活動を達成した。WEB+DB PRESSの特集記事で、Ruby 2.5における処理系自体の最適化の話と、Rubyのコードの最適化の話を書かさせていただいた。
8ページだけでもものすごい労力がかかったので、今後もし本を出したくなった時の参考になった。
WEB+DB PRESS Vol.103の特集記事「Ruby最前線」で、Ruby 2.5で高速化された機能とその仕組みや、2.5で2倍高速化されたERBを題材にRubyのコードのパフォーマンスチューニング方法について書かせていただきました。よろしくお願いします!! https://t.co/FZpfkC98Rz
— k0kubun (@k0kubun) February 13, 2018
ホッテントリ
意識が高くなって英語のブログを書くようになった反動で日本語の記事は減った。スライドも含め、ブクマがついてたのはこのへん。







英語で書いた奴はこういう感じ
| タイトル | claps | |
|---|---|---|
| 1. | The method JIT compiler for Ruby 2.6 – k0kubun – Medium | 944 |
| 2. | Ruby 2.6 JIT - Progress and Future – k0kubun – Medium | 460 |
| 3. | Benchmark Driver Designed for Ruby 3x3 – k0kubun – Medium | 195 |
最初の奴は英語版と日本語版両方書いたけど、これは本当に大変だったので、両方の言語で書くというのはもうやらないと思う。適当に棲み分けてやっていこうと思う。
OSS活動
GitHubで結構芝が生えてたけど、そのうちprivateなコミット(仕事)が5000くらいで、publicなコミットは2500くらいだった。
登録してる中だけで上に8人もいるのか / 私は2018年にGitHubで7444コントリビュートし、Findy内で9位でした。月間の最大は934 (8月)、一日あたりの平均は21.1/日でした。 https://t.co/p695hkqyyM #findy #コントリビューションオブザイヤー
— k0kubun (@k0kubun) December 19, 2018
今年開発していたOSS
| Star | リポジトリ |
|---|---|
| ★349 | k0kubun/sqldef |
| ★70 | benchmark-driver/benchmark-driver |
新作がsqldefだけで寂しい感じ。というか、これも「このままでは今年は新作無しになってしまう!」みたいな気持ちがあって出した奴でもある。benchmark-driverもほとんど今年に完成させたようなものなのでいれておいた。
Contribution
Rubyに636コミットしていて、何人かいるフルタイムコミッターよりコミット数が多かった。JITの開発に加え、MinGWやJIT用のCIを新たに加えたり、CIを安定化させたり、ベンチマーク環境を刷新したり、といった変更をしていた。
2019年は
JITでRailsアプリが高速化できるようにしたい。そのために、JITがある他の処理系の実装を読んだりいじったりしてみようと思っている。それが落ちついたら、今知らない技術で何か新しいものを作るのをまたやっていきたい。
2019年もどうぞよろしくお願いします。
リモートでアメリカの大学院のCSの授業を取ってみた話
Armの福利厚生プログラム FlexPot
私が所属しているトレジャーデータは今年Armに買収され、福利厚生周りがArmのものに刷新された。
その中にFlexPotというものがあり、自己啓発にお金をつかってその領収書を会社に出すと、1年間の合計で上限XX万円まで会社が負担してくれるというもの。具体的な額の公開情報が見当らなかった*1のでふせておくが、割とがんばって使わないと損だなと感じる程度にはもらえる。
何に使うか考えたところ、私は主に家庭と自分の経済的な理由で大学院に行かず働き始めたものの、だんだん会社に給与的な意味で認めてもらえるようになり今は経済的に余裕ができたので、FlexPotも活用しつつちょっと大学院の授業受けてみようかなという気持ちになった。
スタンフォードの Non Degree Option
アメリカに移住を考えている都合、日本ではなくアメリカの大学院に行った方がアメリカでビザを取るのが有利になるためアメリカの大学院の授業を取ってみようかと思ったが、あんまりアメリカの大学のことを知らないので、Rui Ueyamaさんがブログに書いていて面白そうだなと思ったスタンフォードの授業を取ってみることにした。リモートで単位が取れるからというのもある。
卒業できるレベルまで単位を取るのに必要な授業料が高いので、働きながら自分が勉強もこなせるのかとりあえず試しに1つだけ受けてみたかったというのと、そもそも私の学部時代の成績は微妙*2なので、一度履修生として授業を取って内部で良い成績を取るなどしないと、卒業できるコースで出願しても落とされるのではないかという懸念もあり、卒業できないものの後で単位をtransferすることが可能なNon Degree Optionで出願することにした。
出願
Webでポチポチした後、過去に卒業した大学から英語の成績証明書をスタンフォードに郵送すると出願できる。郵送は時間がかかるので、スキャンしてpdfにしてメールで送ると早めにプロセスが進む。ちなみに国際便の郵送をした方は失敗したのか数週間後に返送されてたので、少なくともNon Degree Optionではコピーだけで通ってる気がする。
あと、パスポートのコピーも送らないといけないのだけど、それに全く気付いておらず期限の数時間前くらいに "Please submit ASAP" というメールが来ていて大変だった記憶がある。
授業料
実は上記に加えて、最初に取る単位の授業料を払ってやっと申請が完了になる。つまり受けられるかもまだわからない授業の費用を払うことになるのだが、落ちた場合は返金されるので、クレカの利用可能枠が圧迫されて困った以外の心配はなかった。
授業ごとに取れる単位数が違い、単位数に応じてその授業の費用が変わる。私が取った授業は5単位だったため、6300ドルだった。これはほぼ70万円で、私の大学時代の半期の(複数の授業が受けられる)授業料が半額免除で13万くらいだったことを考えると、高い感じがする。
受講方法
クオーターで授業が区切られており、秋期の9〜12月で週2回80分の授業を受けていた。実際の授業のあと2時間以内にビデオがアップロードされ、リモートの人はそれを見て授業を受ける。英語なんだけど、先生の話すスピードがゆっくりめかつ割と滑舌がよくて聞き取りやすい感じだったので大体1.5〜1.75倍速で再生していたため、46〜53分くらいで受講できる。
私の授業では宿題が毎週出て、難易度に応じて2時間〜休日丸々2日くらいかかる感じだった。あと、これは授業によるのかもしれないがLabというのも毎週あり、テキストが渡され任意の時間に実験室で先生に質問しながら取り組むような奴なのだが、当然リモートだと参加できないため普通に宿題が毎週1個増えるような感じになるが、成果物は2時間取り組んだ後の内容の理解度に応じた質問フォームを埋める程度なのと、宿題に比べると物量が少ないので大体1〜2時間で終わる。
上記を総合すると、毎週最低5時間、運が悪いと土日が完全に潰れることを覚悟しないといけない。2つ同時に授業を受けるなら、1週間に土日が2つ必要になる可能性があることになるので、有給が必要になるかも。
試験
秋期では、11月頭に2時間の中間テストが1回と、12月中旬に3時間の期末テストが1回あった。
リモートで試験を受ける場合、ある条件を満たす人をExam Monitorとして申請し、その人に試験監督をしてもらわないといけない。家族や友人はダメで、会社の上司やHRの人にお願いするなどしなければいけない。
スタンフォードのリモート受講ではこれが唯一面倒なポイント*3で、現地で試験が始まってから24時間の期間に、全く業務に関係ない目的のために同僚の時間を2〜3時間確保しないといけないことになる。私の場合試験が両方Pacific Timeの金曜日だったので、JSTでは土曜の午前3:30みたいな意味不明な時間で始まるため、同僚の休日出勤を避けるために試験開始前の24時間以内でもいいかお願いするところから始まる。これは許されたが、上司の一人は金曜の都合がつかず月曜にできないか依頼したところそれは通らなかったため、二人目の上司に依頼することになった。
Exam Monitorになった人は、メールで問題のpdfをもらい印刷し、2〜3時間の監視の後同じ紙をスキャンしてメールで送り返すのだが、試験の2時間前とかに送られる問題のpdfのメールが、期末試験の時、中間試験の時に依頼した上司に(前日に宛先を先生にダブルチェックしたにも関わらず)送られてしまい、かつUSでは夜の時間のやり取りなので反応も遅いため試験開始の10分前くらいまでバタバタしてギリギリ間に合う感じだった。本当に面倒なので、試験の日だけは現地で受けられるような状態じゃないと辛い*4と思う。
あと、私は松江で行なわれるRuby World Conferenceの2日目と中間試験が被ったため、1日目にRuby Prizeを受賞してスピーチをし100万円をもらった後、2日目は上司に試験監督をしてもらうためさっさと東京に帰っている一見失礼な人間になっていた。カンファレンスと日程が被るかどうかも注意しないといけない。
松江にいると思ってたk0kubunさんのドッペルがオフィスにいて二度見した
— Ryuta Kamizono (@kamipo) November 2, 2018
CS107: Computer Organization & Systems
最近RubyのJITコンパイラの開発をしているのもあり、低レイヤープログラミングっぽい授業があったらそれを受けたいなと思って授業を探していたところ、CS107が一番それっぽかったのでこれを取ることにした。 なお、Ruiさんのスタンフォードのコンピュータサイエンスの授業の感想という記事でもCS107の内容について解説されているが、この記事の存在は受講し始めてから気付いた。
内容
シラバスにもっと丁寧に書いてあるが、私の記憶に残っているものの中では、CS107は大体以下の内容をカバーしていた。
前半はとにかく難易度が低い。Cで普段言語処理系を開発してるような人が受けても得るものはほとんどない。が、課題はセル・オートマトン、UTF8の扱い、Cのライブラリ関数の実装を読みながらUnixコマンド(getenv, which, cat, tail, uniq, ls, sort)を実装しまくるといった内容で、毎回丁寧にコードを添削してもらえるので、C言語を学びたい人にとっては素晴らしい題材になると思う。
後半は学ぶ内容のレベルがちょうどいい感じだった。大学でアセンブリ言語でプログラミングするような授業があったのでそこは復習みたいな感じになったが、初めて知った(か単に忘れていた)ことが割とあったし、課題も試験もかなり練習になる感じなのでよかった。浮動小数点数の仕組みもふんわりとは理解してたけど、バイナリ表現を試験で回答できる程度に理解したのも初めてな気がする。GCCがコード生成の過程でどういう最適化をやってるかを少しだけでも理解しておくと私のJITの開発にはダイレクトに役に立つし、課題でmallocを2パターン実装するのも面白かった。
あと、2年前の期末試験問題とかを見るとELFのシンボルテーボルといった話題にも触れられていたようだが、今年はそれが含まれていなかったのは少し残念だった。
成績
Aだった。GPAにすると4.0で、上にA+があるらしい。テストも別に最高点というわけでもなく、体調崩してる間にLab一つすっぽかしたりしてるので、A+じゃないのはまあしょうがない気がする。
所感
11月にUS出張していた期間がこれと被っていたので、現地で受講したり図書館行ったりすることも可能だったのだけど、体調を完全に崩していて諦めたのがちょっと残念だった。まだキャンパス入ったこともない。
授業1つ取ってるだけで大分忙しくなるので、次授業受けるならもう少しJITの開発が落ちついて暇になったタイミングかなあと考えている。
SQLで羃等にDBスキーマ管理ができるツール「sqldef」を作った
sqldefのリポジトリ
これは何か
Ridgepoleというツールをご存じでしょうか。
これはRubyのDSLでcreate_tableやadd_index等を書いてスキーマ定義をしておくとそれと実際のスキーマの差異を埋めるために必要なDDLを自動で生成・適用できる便利なツールです。一方、

で言われているように、Ridgepoleを動作させるためにはRubyやActiveRecordといった依存をインストールする必要があり、Railsアプリケーション以外で使う場合には少々面倒なことになります。*1 *2
そこで、Pure Goで書くことでワンバイナリにし、また別言語圏の人でも使いやすいよう、RubyのDSLのかわりに、誰でも知ってるSQLでCREATE TABLEやALTER TABLEを書いて同じことができるようにしたのがsqldefです。
使用例
現時点ではMySQLとPostgreSQLに対応しているのですが、このツールはmysqlコマンドやpsqlコマンドとインターフェースを揃えるため、 それぞれのDBに対しmysqldef、psqldefという別のコマンドを提供しています。
README用にgifアニメを用意しておいたので、こちらで雰囲気を感じてください。
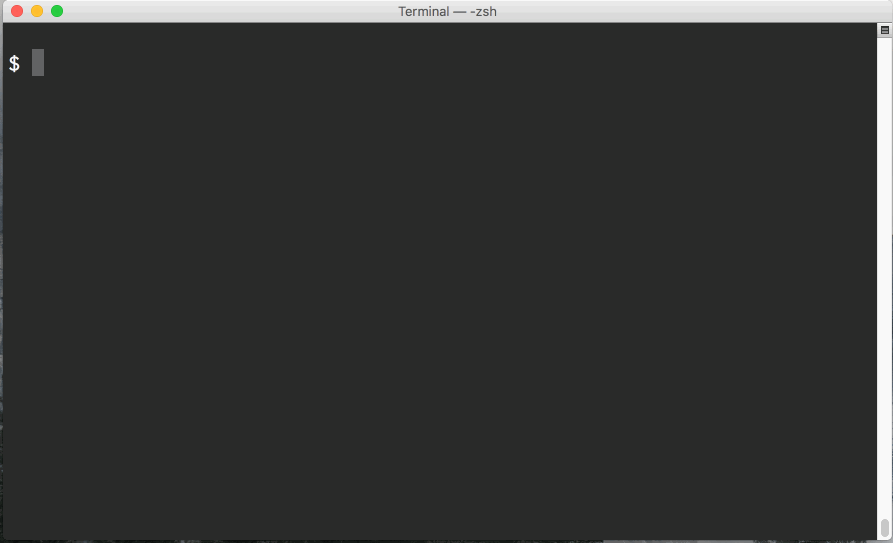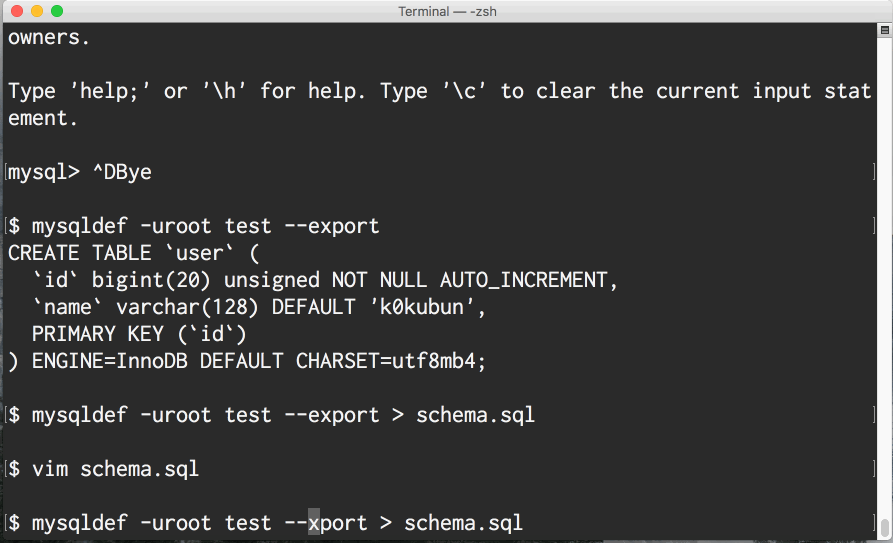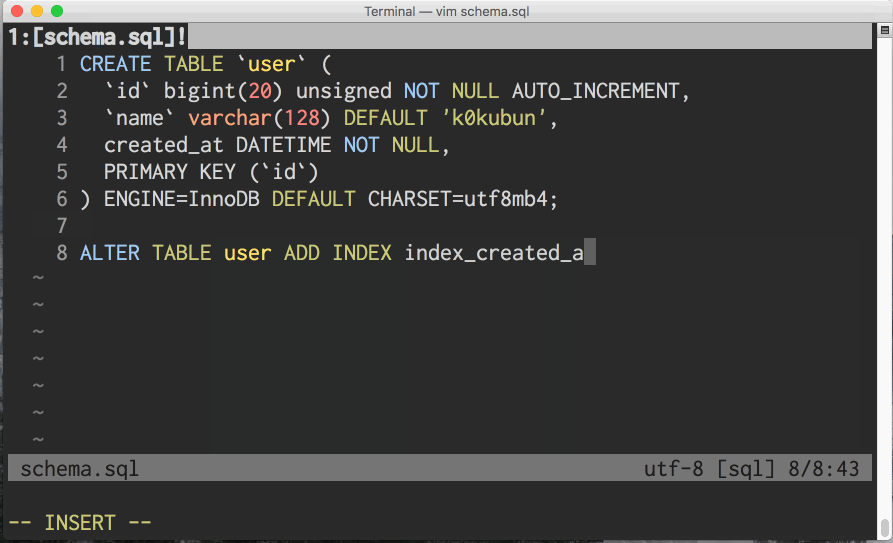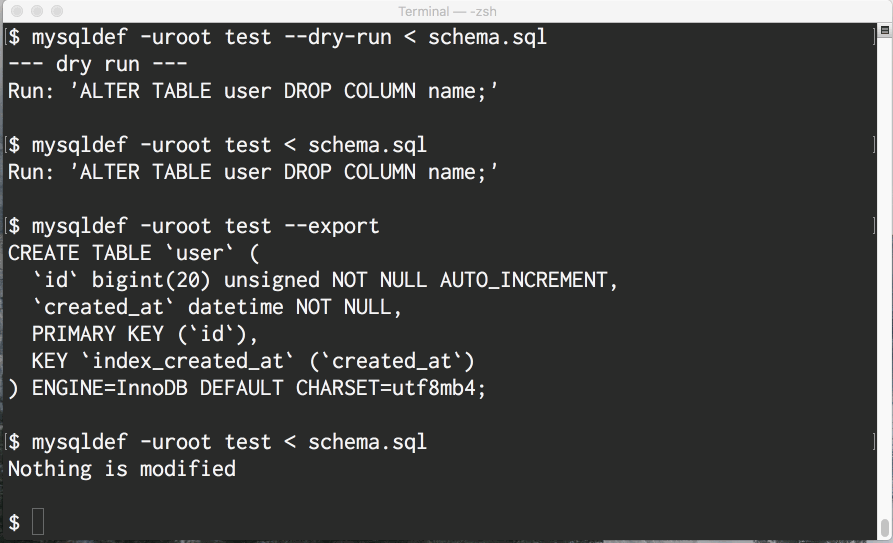
どうやって動いているのか
mysqldef
簡単ですね。go-sql-driver/mysqlというPure GoのMySQLのDBドライバを使っており、mysql(1)やlibmysqlclientに依存していません。
psqldef
これもlib/pqというPostgreSQLのDBドライバがPure Goのため、こちらもpsql(1)やlibpqに依存していません。
pg_dump への依存は、クエリだけでスキーマを取れるようにし、そのうちなくせたらいいなと思ってます。
実装済の機能
- MySQL
- カラムの追加、変更、削除
- テーブルの追加、削除
- インデックスの追加、削除
- 外部キーの追加、削除
- PostgreSQL
- カラムの追加、削除
- テーブルの追加、削除
- インデックスの追加、削除
- 外部キーの追加、削除
あまり無駄にシミュレートをがんばりたくないのと、どうせ対応しても僕は使わないので、CREATE TABLE, CREATE INDEX, ALTER TABLE ADD INDEX の羅列以外の入力に対応していません。DROPは常に書いてあるものを消すことで生成する想定です。テーブルやカラムにリネームが必要な場合は手動でリネームを発行して --export し直す想定です。
お試しください
まだ本番じゃ全然使えないクオリティなんですが、ISUCONとかでは割と便利に使えるかもしれません。 sqldefがそのまま使えるスキーマ定義が置いてあることが多いようですし。
そういうわけで、よろしくお願いします
追記: schemalexとの比較
schemalexの作者の方にschemalexと比較して欲しいというコメントをいただいているので軽く補足します。
SQL同士を比較してSQLを生成する既存のマイグレーションツールはいろいろあるんですが、その中でもGo製でMySQL向けにスキーマ生成ができるschemalexが既にある中で何故一から作ったかというと、正直なところ完全に調査不足で羃等にスキーマ管理するツールをRidgepole以外に知らなかったことによります。
その上で、2018年8月現時点でsqldefに実装されている機能とschemalexを比較すると、それぞれ主に以下の利点があると思います。
- schemalex
- sqldef
どれもお互い今後の開発次第で解決できる問題ですが、おそらく思想的に変わらなそうなのはそれぞれ最後のCLIに関する部分でしょう。なので、私が羃等なスキーマ管理ツールのユースケースとして想定している以下の状況における、それぞれの現時点での使い方を比較したいと思います。
DBサーバーのスキーマのexport
schemalex
$ echo "" | schemalex -o schema.sql - "mysql://root:@tcp(localhost:3306)/test"
BEGIN; や COMMIT; が含まれているのを消す必要があるため、私が把握していないだけでより正しい方法があるかもしれません。
sqldef
$ mysqldef -uroot test --export > schema.sql
Pull Requestマージ後に実行されるDDLの表示、適用
schemalex
もともとgit-schemalexとして開発されていた機能が活用できるため、こちらはschemalexが便利なユースケースだと思います。
# PRチェックアウト時、masterのスキーマ適用のためのDDL表示 $ schemalex "mysql://root:@tcp(localhost:3306)/test" "local-git://.?file=schema.sql&commitish=master" BEGIN; SET FOREIGN_KEY_CHECKS = 0; CREATE TABLE `users` ( `id` BIGINT (20) DEFAULT NULL, `name` VARCHAR (40) DEFAULT NULL ); SET FOREIGN_KEY_CHECKS = 1; COMMIT; # PRチェックアウト時、masterのスキーマの適用 $ schemalex "mysql://root:@tcp(localhost:3306)/test" "local-git://.?file=schema.sql&commitish=master" | mysql -uroot test # マージ後に実行されるDDLの表示 $ schemalex "mysql://root:@tcp(localhost:3306)/test" schema.sql BEGIN; SET FOREIGN_KEY_CHECKS = 0; ALTER TABLE `users` ADD COLUMN `created_at` DATETIME NOT NULL; SET FOREIGN_KEY_CHECKS = 1; COMMIT; # マージ後のスキーマの適用 $ schemalex "mysql://root:@tcp(localhost:3306)/test" schema.sql | mysql -uroot test
sqldef
sqldefは標準でgit連携を持っていないため、mysqlコマンドが不要なかわりにgitコマンドが必要になります。*4
# PRチェックアウト時、masterのスキーマ適用のためのDDL表示 $ git show master:schema.sql | mysqldef -uroot test --dry-run -- dry run -- CREATE TABLE users ( id bigint, name varchar(40) DEFAULT NULL); # PRチェックアウト時、masterのスキーマの適用 $ git show master:schema.sql | mysqldef -uroot test -- Apply -- CREATE TABLE users ( id bigint, name varchar(40) DEFAULT NULL); # マージ後に実行されるDDLの表示 $ mysqldef -uroot test --dry-run < schema.sql -- dry run -- ALTER TABLE users ADD COLUMN created_at datetime NOT NULL; # マージ後のスキーマの適用 $ mysqldef -uroot test < schema.sql -- Apply -- ALTER TABLE users ADD COLUMN created_at datetime NOT NULL;
なおBEGIN;やCOMMIT;は表示していませんが、applyはトランザクション下で行なわれます。
最新のスキーマファイルのDBサーバーへの適用
schemalex
# masterチェックアウト時、スキーマ適用のためのDDL表示 $ schemalex "mysql://root:@tcp(localhost:3306)/test" schema.sql BEGIN; SET FOREIGN_KEY_CHECKS = 0; ALTER TABLE `users` ADD COLUMN `created_at` DATETIME NOT NULL; SET FOREIGN_KEY_CHECKS = 1; COMMIT; # スキーマの適用 schemalex "mysql://root:@tcp(localhost:3306)/test" schema.sql | mysql -uroot test
sqldef
# masterチェックアウト時、スキーマ適用のためのDDL表示 $ mysqldef -uroot test --dry-run < schema.sql -- dry run -- ALTER TABLE users ADD COLUMN created_at datetime NOT NULL; $ mysqldef -uroot test < schema.sql -- Apply -- ALTER TABLE users ADD COLUMN created_at datetime NOT NULL;
まとめ
どちらのCLIがユースケースにマッチするかは要件によると思いますが、2018年8月現時点では、MySQLの用途においては実績のあるschemalexを採用するのが現実的だと思います。私自身は自分の自由が効くsqldefをMySQLでも使いメンテを続けるつもりのため、時間が経てばこの問題は解決するでしょう。
一方PostgreSQLでワンバイナリのスキーマ管理ツールが必要な場合は、PostgreSQL未対応のschemalexに対応を入れるよりはsqldefを使ってしまう方が楽かと思われます。
2021-10-30 edit: おかげ様で様々な会社様から本番利用事例をいただいております。まだまだ全てのケースに対応しているとは言えずissueベースでユースケースのカバーを続けている状態ですが、公開から3年以上経った今、schemalexやskeemaと比べても遜色ない利用実績があると言えるでしょう。
言及例:
- 2018-09-05: sqldef本番投入成功
- 2019-12-07: Web開発を支えるマイグレーションツールについて
- 2020-07-30: Nature Remoから学ぶシステムアーキテクチャと開発プロセス w/ songmu *5
- 2020-11-05: ZOZOTOWNリプレイスにおけるSREの取り組み
- 2021-09-27: sqldefへのSQL Server対応のコントリビュート 〜OSS活動を通して紐解くDBマイグレーションツールの実装〜 - ZOZO TECH BLOG
- その他: 利用者が多くを占める sqldef contributors
*1:例えばRuby以外の言語でアプリを書いてCircleCIでテストする場合、CirlceCI公式のDockerイメージは普通に一つの言語しか入ってないので、アプリ用の言語とRidgepole用のRubyが両方入ったDockerイメージを自分で用意しないといけないですよね
*2:Ridgepoleの作者のwinebarrelさんにコメントをいただいてますが、現在はomnibus-rubyによってRubyを同梱したrpmやdebのパッケージとしても配布されているため、バイナリをダウンロードするかわりにパッケージをダウンロードしてインストールする、ということもできそうです。一方手元でmacOSを使っていたりするとrpmやdebは使えないですし、これはItamaeとmitamaeに関しても言える話ですが、一切依存のないバイナリ一つで動作する方が何かと管理が楽であろうという考えのもとこれらのツールを作っています。
*3:schemalexでもこのPR https://github.com/schemalex/schemalex/pull/52 で同様の機能が実装されると理解していますが、未マージのようです
*4:GitHubにリポジトリを置いていたらCIからcloneしてくる際に必要になるので、普通は入ってるとは思います
*5:00:25:10~: "多分sqldefの方が使われていると思うんですけど" と言及いただきました
RubyのJITに生成コードのメモリ局所性対策を入れた話
JITすればするほどRailsが遅くなる問題
Rubyの次期バージョンである2.6には、バイトコードをCのコードに変換した後、gcc/clangでコンパイルして.soファイルにしdlopenすることで生成コードのロードを行なう、MJITと呼ばれるJITコンパイラが入っているのだが、マージしたころのツイートにも書いていた通り、Railsで使うとより多くのメソッドがJITされるほど遅くなってしまうという問題があった。
結果、"MJIT slows down Rails applications"というチケットが報告されることとなり、昨日までの5か月の間閉じることができなかった。
元の構成

対策を始める前のMJITは大雑把に言うとこういう感じだった。メソッド1つごとに1つの.soファイルが作られ、ロードされる。
無制限にロードしまくるわけではなく、--jit-max-cacheオプションで指定した数(デフォルトでは1000)までしか生成コードを維持しないようになっており、JITされた数が--jit-max-cacheに到達すると、「呼び出し回数が少なく、かつ現在呼び出し中でないメソッド」と「メソッドがGC済のメソッド」向けにdlcloseを行なってから、他の呼び出し回数の多いメソッドのJITを開始する。
遅くなる理由
JITのためにgccやclangが走っている最中は、そこにリソースが取られるからかある程度遅くなってしまうのだが、今回報告されたチケットの計測方法では計測中ほとんどコンパイルが走らない状態になっていた。
いくつかのマイクロベンチマークや、ピュアRubyのNESエミュレータでの性能を計測するOptcarrotというベンチマークではJITした方が明らかに速いのだが、先のチケットの計測方法だと遅くなってしまう。この理由は最初は不可解だったが、Optcarrotで普通にベンチを取ると20〜30メソッドくらいしかJITされないのに対し、このRailsでの計測は4000〜5000メソッドがJITされているという大きな違いがあった。
そもそも生成コードの最適化がRailsのコードに対して全然効いてなさそうなのも問題なのだが、最適化の余地が全くないようなただnil*1を返すだけのメソッドをたくさん定義して呼び出してみると、定義して呼び出すメソッドの数が多いほど遅くなることが発見された。
perfで計測してみると、遅くなっているのはicacheにヒットせずストールする時間が長くなっているのが原因のようで、それはメソッドごとに.soをdlopenしていることで生成コードが2MBおきに配置されてしまっておりメモリ局所性が悪いことが原因と結論づけた。*2
どうやって解決するか
解決策1: ELFオブジェクトを直接ロード
僕がこれに関する発表をRubyKaigiで行なってすぐ、shinhさんがELFオブジェクトを自力でロードしてくるパッチを作ってくださっていた。試してみると、ロードにかかる時間を遅くすることなく、40個くらいのメソッドを呼び出してもJIT無効相当の速度が出ていた。
一方で、shinhさん自身がブログで解説しているが、これを採用するとなると以下のような懸念点があった。
- ELFを使うOSでしか動かない
- (現状のパッチだと)ロードしたコードのデバッグ情報がgdbで出ない
- ローダ自体の保守やデバッグが大変そう
- 生成コードのメモリ管理が大変 (1GB固定アロケートか、遅くなるモードのみ実装されている)
そのためこれは直接採用はせず、以下の手法の評価にのみ利用した。
解決策2: 全てのメソッドを持つsoファイルを作ってdlopen
別々の.soになっているから問題が起きるわけなので、何らかの方法でコンパイル対象のメソッドが全て入ったsoを生成し、全てのコードをそこからロードしてくれば良いという話になる。コンパイル対象のメソッドの数が適当にハードコードした数に達したらまとめてコンパイルしてロードするようにしてみたら、実際速かった。
考慮したポイント
しかし、4000メソッド(計測に使われているRailsアプリのエンドポイントを叩いて放置するとコンパイルされる数)くらいをまとめてコンパイルすると普通に数分かかったりするので、この最適化をどのタイミングでどう実現するかは全く自明でない。
その戦略を考えるのが結構大変だったので、RubyKaigiの時点では定期的にまとめてコンパイルするだけのスレッドを新たに立てるつもりだったが、実装が複雑になるのでMJIT用のワーカースレッドは増やさないことにした。
その上で、短期間に少量のメソッドをコンパイルするOptcarrotでのパフォーマンスを維持しながら、数分かけて大量のメソッドをコンパイルするRailsでの性能を改善するため、以下の要素を考慮して設計することにした。
- 初めてコンパイル+ロードされるまでの時間
- soをまとめた後コンパイル済メソッドそれぞれのためにdlsym + ロックを取って生成コードを差し替える時間
- 生成コードの数が溢れた時にメインスレッドで生成コードをdlcloseする時間
- まとまったsoのコードに差し替えられるまでの時間
- メモリ使用量
- Ruby実行中 /tmp に持ち続けるファイルの数とサイズ
より上にある奴がより優先度が高く、下の方は(どうせ大した量使わないのもあり)どうでもいいと思っている。
最終的な構成

上記の1のためにワーカーはメソッドを1つずつコンパイルし、4のためにそのコンパイル結果の.oを /tmp に残し続けることにし、一方で一つ.oが増える度に一つのsoにしてロードし直してると2が線形に重くなって厳しいので4は多少犠牲にして一定回数おきにだけまとめてロードすることにして、そうするとある程度3や5が小さくて済み、6に関してはどうにかしたくなったら複数の.oファイル達を1つの.oにまとめれば良いだろう、という方針で作り始めた。
で、速度に関してはその方針でいいとして、メモリ使用量を考慮すると上記の図の"Sometimes"にあたる頻度がちょっと難しい。現状の実装では、呼び出されている最中の生成コードをそのフレームの外からVM実行に置き換えるOSR*3を実装できていないので、あるタイミングで1つの.soにまとめて生成したコードがどのフレームで使われているかを新たに管理するようにしないと、使われなくなったコードの破棄*4ができないのだが、それをやるとコードが結構複雑になる上に結局メモリ使用量も増えてしまう問題があり、あまりやりたくない。
それをサボる場合、頻度を上げれば上げるほどメモリリーク的な挙動になる*5わけなので、とりあえず キューイングされた全てのメソッドがコンパイルされた時 か --jit-max-cacheに達した時 だけ一つの.soにまとめてロードする処理をやる状態でコミットした。
OSRは他の最適化にどの道必要なので、長期的にはOSRを実装して任意のタイミングで古い生成コードを全て破棄できる状態にしようと思っている。
ベンチマーク
チケットの報告に使われているDiscourseというRailsアプリの、ウォームアップ*6後の GET / リクエスト100回で、以下のものを計測した。
- trunk: r64082
- trunk JIT: r64082 w/ --jit
- single-so JIT: r64082 + 今回のパッチ w/ --jit
- objfcn JIT: shinhさんのobjfcnをr64082からrebaseしたもの
レスポンスタイム(ms)
| trunk | trunk JIT | single-so JIT | objfcn JIT | |
|---|---|---|---|---|
| 50%ile | 38 | 45 | 41 | 43 |
| 66%ile | 39 | 50 | 44 | 44 |
| 75%ile | 47 | 51 | 46 | 45 |
| 80%ile | 49 | 52 | 47 | 47 |
| 90%ile | 50 | 63 | 50 | 52 |
| 95%ile | 60 | 79 | 52 | 55 |
| 98%ile | 91 | 114 | 91 | 91 |
| 100%ile | 97 | 133 | 96 | 99 |
速度増加の割合
小さい値の方が良く、 太字 が速くなっている箇所。
| trunk | trunk JIT | single-so JIT | objfcn JIT | |
|---|---|---|---|---|
| 50%ile | 1.00x | 1.18x | 1.08x | 1.13x |
| 66%ile | 1.00x | 1.28x | 1.13x | 1.13x |
| 75%ile | 1.00x | 1.09x | 0.98x | 0.96x |
| 80%ile | 1.00x | 1.06x | 0.96x | 0.96x |
| 90%ile | 1.00x | 1.26x | 1.00x | 1.04x |
| 95%ile | 1.00x | 1.32x | 0.87x | 0.92x |
| 98%ile | 1.00x | 1.25x | 1.00x | 1.00x |
| 100%ile | 1.00x | 1.37x | 0.99x | 1.02x |
50%ileと60%ileは微妙だが、1000リクエストする計測でやり直すと50%ileや60%ileのtrunkとの差が1msとかだけになる*7ので、微妙に遅くなるか運が良いとちょっと速いという状態まで改善した。
感想
objfcnに比べ遜色ない効果が出せているし、Optcarrotも仕組み上今回の変更ではベンチマーク結果に影響はないので、生成コードのメモリ局所性の問題に関してはうまく解決できたと思う。Railsで遅くはならない状態にできたので、今度は速くしていくのをがんばりたい。
*2:メソッドごとに実際に2MB使われているわけではないことに関する詳細はshinhさんがブログで解説しています http://shinh.hatenablog.com/entry/2018/06/10/235314
*3:On-Stack Replacement
*4:対応するハンドルのdlclose
*5:というかこれの対策は今入ってないわけだけど、まあ2.6のリリースにOSRが間に合わなそうなら適当な回数で.soをまとめる処理をやめるようにしようと思っている
*6:詳細は https://github.com/ruby/ruby/pull/1921 を参照
*7:最初からそうやって計測すればいいのだけど、一応起票されたチケットのやり方に合わせた
個人で運用するKubernetesクラスタ
Kubernetesの使用感に興味があってaws-workshop-for-kubernetesというのを先週やり、ちょうどEKSがGAになった直後だったのでEKSが試せたのだけど、まあ最初からマネージドだとあまり面白みがないし金もかかるので、個人のVPSで動かしてた奴を全部Kubernetes上で動かすようにしてみている。
まだ本番で運用した知見みたいなのが貯まってるわけではないのだが、公式のドキュメントを中心に読んでいても単に動かし始める段階で結構ハマって時間を消費したので、これから同じようなことをやろうとしている人向けに備忘録を兼ねて使用感や知見をまとめておくことにした。
Kubernetesは今でもalphaやbetaの機能が多く、今後この記事の内容も古くなることが予想されるので、なるべく公式のドキュメントへのリンクを置くのを意識して書いてある。
構成
現時点で、ConoHaで借りたサーバー (1GB 2コア x 2, 512MB 1コア x 1) で以下のような構成のものを動かしている。

Kubernetes周りの細かい用語は以降で説明するが、要は以下の5種類のものがKubernetesからDockerでデプロイされている。
- Reverse Proxy: nginx-ingress-controller
- Application Server: Rails
- Worker: 非同期ジョブワーカー, Chatbot
- Database: MySQL
- Cron Job: TLSサーバー証明書更新
コスト
このキャパシティだとメモリもCPUも割と余裕がない感じなのだが、落ちても困らない純粋な趣味*1で立てている赤字サーバーなので意図的に最小限のコストで走らせている*2。
Ubuntu 16.04→Ubuntu 18.04に式年遷宮しておこうと思った関係で今回ついでにVPSも乗り換えていて、 雑に調べた中だとConoHaのメモリ1GBプランがメモリ/円, CPUコア数/円で見て最もコスパが良さそうなのでなるべくこれを並べることにしているが、元のVPSの費用が安かったので1台はケチって512MBのプランにしている。
もともとは1年課金で初期費用4000円 + 月2380円のVPS(4コア, 4GB RAM)で動かしていたのが、1時間課金で初期費用0円 + 合計月2430円になったので、コストはほとんど変わっていない。 試験的にDBもKubernetes上で動かしてみたけど、あとで月630円のサーバーを潰して月500円のDBサーバーに移そうと思ってるので最終的には安くなると思う。
お仕事ならクラスタを保守・運用する人件費の方が余裕で高くつくと思うのでEKSのFargate起動タイプが出るまでは大体GKEを選ぶのが良いのだろうと思っているが、真面目には調べていない。
Kubernetesクラスタの作成方法
AWSやGCEで立てるならkopsとかを使うのが普通なのだと思うが、まあその辺のVPSではそういうのは使えなさそうなのでいくつかのツールを検証した。最終的にkubeadmに落ちついたのだが、それ以外を選択しなかった理由についても書いておく。
conjure-up
https://kubernetes.io/docs/getting-started-guides/ubuntu/
上記のUbuntu向けのGetting Startedで使われている通り、多分Ubuntuではconjure-upで立てるのが公式のお勧めなのだろう。ターミナル全体を支配する感じのウィザードが立ち上がり、いくつか選択肢を選ぶだけでセットアップできる。
僕が使った時は普通にsnapでconjure-upを入れたところバグにヒットしたがこれはchannelをedgeにしたら直った。が、これはkubeadmと違ってDocker以外にKVM等の仮想化レイヤーも挟まることになっていて、conjure-upでmaster nodeをセットアップするとConoHaの3コア2GBのマシンでもリソースを使い尽くして死に、その1つ上の4GBのマシンはちょっと高くなってしまうので採用を見送った。
minikube
https://kubernetes.io/docs/setup/minikube/
これもVirtualBox等の仮想化ドライバの上でKubernetesが立ち上がる奴なのだが、使いやすくてよくできている。 手元で開発用に立ち上げるツールとしてはこれが一番いいのではなかろうか。
minikubeを使うためにはVT-xかAMD-vの有効化が必要で、手元のマシンではBIOSで有効にできたがConoHaでは無効だったのでこれも今回は採用できなかった。
kubeadm
https://kubernetes.io/docs/setup/independent/create-cluster-kubeadm/
kubeadmでKubernetesをセットアップすると、master nodeとworker nodeの両方でシングルバイナリのkubeletがsystemd等からホストで直に起動され、kube-apiserver, kube-controller-manager, kube-dns, kube-proxy等その他のコンポーネントはホストのdockerdにぶら下がる形で動く。
そのため余計なオーバーヘッドが少なめで、実際ConoHaのメモリ1GB 2コアのマシンでmaster nodeが割と安定して稼動してくれる。512MB 1コアのマシンだとkubeadm initでCPU使用率が爆発してセットアップが完了しないので、masterはそれ以上ケチることはできない。kubeadm joinするだけのworker nodeは上述の通り512MB 1コアのマシンでも動く。
kubeadm initでmaster nodeを立ち上げた後kubeadm resetで全て綺麗にできるので、色々いじりすぎて何かよくわからないけど動かない状態になってしまって最初からやり直したいという時に、マシンを作り直さなくてもkubeadm resetするだけで良かったのが便利だった。ただしmulti-masterに対応してないのが欠点っぽい。
kubeadmをmitamaeから叩く形でmaster nodeのセットアップは完全に自動化しているが、worker nodeに関してはkubeadm joinする部分だけ一時的なトークンが必要な都合自動化を保留している。
名前解決ができない問題
そもそも僕は最初にkubeadmを試していて、何故conjure-upやminikubeも触るはめになったのかというと、kubeadmでKubernetesクラスタを立ち上げると、何故かkube-dnsで外部のサービス(*.cluster.localとかじゃなくて例えばslack.com等)の名前解決ができなかったためである。
そのためにPodのネットワークアドオンもCalico, Canal, Flannel, Weave Netなど色々試し、最終的にkubeadmなしでmaster nodeをセットアップするのも挑戦することになった(死ぬほど面倒なのでやめた)。ConoHaのファイアウォールも疑ったけど手元の開発マシン(Ubuntu 18.04)でも再現した。minikubeではこの問題はなかった。
で、何日かハマった後、Customizing DNS Serviceというドキュメントをを参考に以下のようなConfigMapを作りkubectl applyすることでこの問題は解決した。upstreamNameserversの実際の値はConoHaコントロールパネルでDNSサーバー1, 2にあったものを使用している。
apiVersion: v1 kind: ConfigMap metadata: name: kube-dns namespace: kube-system data: upstreamNameservers: | ["XXX.XXX.XXX.XXX", "YYY.YYY.YYY.YYY"]
何故kubeadmだとこのような問題が起きるのかはまだちゃんと調べていないが、 *3 内部DNSもちゃんと名前解決できているし今のところ特に困ってはいない。
各コンポーネントの動かし方
冒頭の分類別に、どうやって動かしているかを僕が実際に古いVPSから移してきた順に解説していく。 実際のYAMLをこの記事と一緒に読みやすいように名前等を変えたものを以下の場所に置いておいた。
https://github.com/k0kubun/misc/tree/kubernetes
あくまで参考用で、いくつかはsecretやnodeSelectorの都合そのままkubectl applyしても恐らく動かないことに注意されたい。
各見出しの先頭に、一番参考になると思われるドキュメントへのリンクを貼っておく。どう考えてもそっちを読んでもらった方がいいので、ここでは要点しか解説しない。
Worker
https://kubernetes.io/docs/tasks/run-application/run-stateless-application-deployment/
最初に練習用にRuby製のChatbotであるRubotyをSlack向けに立てた。 最近開発しているRuby 2.6.0-preview2のJITコンパイラで動かしているため、ネイティブコードで高速にレスポンスが返ってくる。

Railsアプリからの非同期ジョブを受けるワーカーも同じ方法で立てられる。 この類のアプリケーションはデプロイ時にダウンタイムがあってもそれほど困らないので、難易度が低い。
単にPodを作るだけでもデプロイは可能だが、Deploymentリソースを作ってそいつにPodを作らせることで、 OOMとかで殺されても再度勝手にPodが作られるようにすることができる。それ以外それほど考えることはなさそう。
別途Vaultとかを設定しなくとも、Secretリソースでetcdに保存しておいた秘匿値を参照できる。 ワーカーのYAMLの方に例を書いてあるが、他の平文と環境変数と並べて書けて便利。
また、次に解説するMySQLへは、"default"ネームスペースに"mysql"という名前のServiceを作っておくことで、mysql.default.svc.cluster.localという名前でアクセスできる。
Database
https://kubernetes.io/docs/tasks/run-application/run-single-instance-stateful-application/
https://kubernetes.io/docs/tasks/run-application/run-replicated-stateful-application/
上記は2つともMySQLの例だが、CassandraとかZooKeeperの例もドキュメントにあり、状態を持つアプリのデプロイもPersistentVolumeやStatefulSetsなどにより割と手厚いサポートがある。
まあ、普通の神経してたらDBはRDSとか使うのが普通だし、マルチテナントなコンテナクラスタに状態のあるアプリをデプロイしても実際はあまり嬉しくないと思うが、一応以下のようなYAMLでできる。
ホストの適当なパスを選んでPersistentVolumeというリソースを作っておくと、PersistentVolumeClaimというリソース経由でPodにボリュームをアタッチしてコンテナにマウントできる。 そのボリュームでのディスク使用量に制限をかけられるのが便利なところだと思う。 *4 MySQLの場合/var/lib/mysqlがコンテナを停止してもホストに残るようにしておけば良い。
Reverse Proxy
https://kubernetes.github.io/ingress-nginx/deploy/
https://kubernetes.io/docs/concepts/services-networking/ingress/
Serviceというリソースでも外部へのサービスの公開は可能だが、僕の場合はTLS terminationをやるためにIngressリソースを使う必要があった。 しかし、Ingressというのは"ingress controller"というのを設定しないと動いてくれないという特殊なリソースで、Serviceと違ってkube-proxy先輩は面倒を見てくれない。
例えばAWSだとALBをバックエンドにしたIngress Controllerを使うことになると思うが、その辺のVPSで立てるならnginx-ingress-controller等を使う必要がある。nginx-ingress-controllerの設定で結構ハマってなかなかパブリックIPからアクセスできる感じにならなかったのだが、最終的に以下のような設定をしたら動いた。
ホスト名とかがヒットしなかった時に使われる--default-backend-serviceは指定しないと起動に失敗する。
またKubernetesでRBAC(Roll-based access control)が有効になっているとnginx ingress controllerは様々な権限を要求してくるので、がんばって権限管理をする必要がある。RBACには権限のリソースにRoleとClusterRoleの2つがあり、それぞれRoleBindingとClusterRoleBindingによってnginx-ingress-controllerのPodのServiceAccountに紐付ける必要がある。
Podのspec.serviceAccountNameでServiceAccountは指定可能だが、デフォルトでは"default"というServiceAccountに紐付いていて、上記の例ではそいつに何でもできるcluster-adminというClusterRoleを紐付けている。良い子は真似しないように。
Application Server
https://kubernetes.io/docs/concepts/services-networking/service/
Ingressから参照するServiceリソースを立てておく必要があるところがWorkerと異なるが、他は基本的に同じ。
静的ファイルの配信はnginxとかに任せるのが定石だけど、まあ設定が面倒になるのでこの例ではRAILS_SERVE_STATIC_FILES環境変数をセットしてRailsにアセットの配信をやらせている。どうせクライアント側でキャッシュが効くのでカジュアルな用途ではこれでいいと思うが、真面目にやるならS3にアセットを上げておいてCDNから参照させるようにするとかがんばる必要がある。
Cron Job
https://kubernetes.io/docs/concepts/workloads/controllers/cron-jobs/
CronJobというリソースでJobリソースを定期実行できる。Kubernetes 1.4だとScheduledJobという名前だったらしい。
僕はこれでLet's EncryptのTLSサーバー証明書の更新をやっている。公式のcertbotはPythonなのが気にいらないのでRuby製のacmesmithというのを使っていて、これもJITを有効にしているため高速に証明書が更新できる*5。
無駄に毎日叩くようにしてあるが、証明書が新しければacmesmith側で更新がスキップされるようになっているので特に問題はない。
実際の更新スクリプトが何をやるかはこのYAMLからは読み取れないようになっているが、curlでhttps://${k8s_host}/api/v1/namespaces/default/secretsにPOSTしてnginx-ingress-controllerが参照しているSecretリソースを更新している。-H "Authorization: Bearer ${x8s_token}"もつけないとUnauthorizedになるが、このトークンの取得方法はこのYAMLのコメントにあるコマンドで見ることができる。
動かしてみてわかったこと
master nodeのエージェントが結構メモリを使う
master nodeにPodをスケジューリングするのはsecurity reasonsのためデフォルトで無効になっているが、まあコストのためにmaster nodeのリソースも普通に使うつもりでいた。
しかしKubernetesのmaster nodeに必要なプロセス達は結構なメモリを使ってしまうので、そのアテは外れた。特にkube-apiserverはメモリ1GBのマシンでコンスタントに25%くらいメモリを使うし、etcd, kube-controller-manager, kubeletもそれぞれ5%くらい使うし、他にも1%くらい使う奴がいっぱいある。設定でどうにかできるなら是非改善したい。
メモリ1GB 2コアのmaster nodeにChatbotを立てるくらいは流石にできたけど、master nodeの余剰リソースにはほとんど期待しない方がいい。 調子に乗ってmaster nodeのリソースを使い切るとkubectlが使えなくなってPodの停止もできなくなるので、マシンの強制終了くらいしかできなくなってしまう。それがsecurity reasonsなのかもしれない。
ちなみにworker nodeでもkubeletやdockerdが動いているため、worker node側も限界までリソースが使えるとは考えない方が良いと思う。
ある程度余裕を持ってキャパシティを見積る必要がある
割と当たり前の話だが、コンテナクラスタに余剰リソースがないと、rolling updateで新しいイメージをデプロイしようとした時に新たなPodのスケジューリングに失敗する。master nodeのリソース使用量が予想外に大きかったので結構ギリギリで今運用してるのだけど、停止時間を作りたくないデプロイをする時に普通に困る*6。
Kubernetesの前身であるBorgの論文だと、バッチジョブとかのプライオリティを下げておき、よりプライオリティが高いタスクのスケーリングの際にそれを犠牲にする(Resource ReclamationやPreemptionと書かれている)運用戦略が語られているが、KubernetesにもPod Priority and Preemptionが存在するので、バッチジョブがある程度ある場合はそいつに融通を効かせるというのもできるかもしれないが、まだ試してない。
感想
普通はDockerコンテナ用意してちょろっとYAML書くだけでデプロイできる基盤があったら便利だけど、この規模の用途で使うなら、master nodeの運用の面倒さとかKubernetesがやたらリソースを食ってくるデメリットの方が高くつきそうなので、アプリはホストに普通に立ててリソース制限はsystemdとかでやるのがいいと思う。
*1:このRailsアプリは自作テンプレートエンジンや自作JITコンパイラに加えGraphQLやReactやwebpackerが使われていたり、RubyじゃなくてわざわざJavaでワーカーを書いたりと、色々好き放題やるために立てている。
*2:落ちても困らないのでkubeadmの推奨スペックを下回るマシンを使っている。Rubyを--with-jemallocでビルドし、UnicornをやめてPumaをスレッドベースで走らせることでメモリ使用量を抑えるみたいなこともやっている。
*3:Ubuntu固有の問題のようです https://inajob.hatenablog.jp/entry/2018/02/28/%E6%9C%8810%E3%83%89%E3%83%AB%E3%81%A7%E6%B5%B7%E5%A4%96VPS%E3%81%A7Kubernetes%E3%82%92%E8%A9%A6%E3%81%97%E3%81%A6%E3%81%BF%E3%82%8B%EF%BC%88kubernetes_v1.9%E7%89%88%EF%BC%89
*4:@nekop さんに訂正いただきましたが、hostPathではランタイムでQuotaの制限はないそうです https://twitter.com/i/web/status/1010037274694770688
*5:まあ当然これは冗談で、長い間走らせ続けるChatbotに比べたらむしろ実際には遅くなるくらいだと思われる